
There are numerous buzzwords associated with RDMA in the context of GPUs: GPU-direct, NvLink, NVLink Fusion, InfiniBand, Quantum InfiniBand, GPUNetIO, and DOCA. This is confusing, but perhaps it doesn’t have to be?
This article is written in the form of a personal memo, attempting to articulate the various technologies and visualize them with a few diagrams.
GPU Direct and RDMA: Marketing vs. Technology. Link to heading
Let’s start in-medias-res, with the confusing GPUNetIO page from the official Nvidia documentation:
Note that the RDMA acronym describes the protocol to enable remote direct memory access from the memory of one computer into that of another without involving the operating system of either one. … It must not be confused with GPUDirect RDMA, which is not related to the RDMA protocol.
Clear, so GPUDirect RDMA is not the same as the RDMA protocol! But, does GPUDirect RDMA use the RDMA protocol at least? I hope so; otherwise, that would be really confusing.
GPUDirect RDMA is one of the technologies enabled by NVIDIA in the GPUDirect family of technologies. It enables the network card to send or receive data directly accessing the GPU memory bypassing the CPU memory copies and Operating System routines. GPUDirect RDMA can be enabled by any network framework working with Ethernet, InfiniBand, or RoCE.
Okay, at least it is clear: GPUDirect RDMA can be implemented on any transport layer, whether it is Ethernet (ETH) or InfiniBand (IB). But, so, what is GPUNetIO and how does it relate to RDMA? Well, the answer is simple. GPUNetIO, is, as its name indicates, a network based implementation of the GPU direct RDMA over a network card. That does not mean that GPU Direct has to be driven from a network card, but only that the GPUNetIO is a specialized version for the network card type.
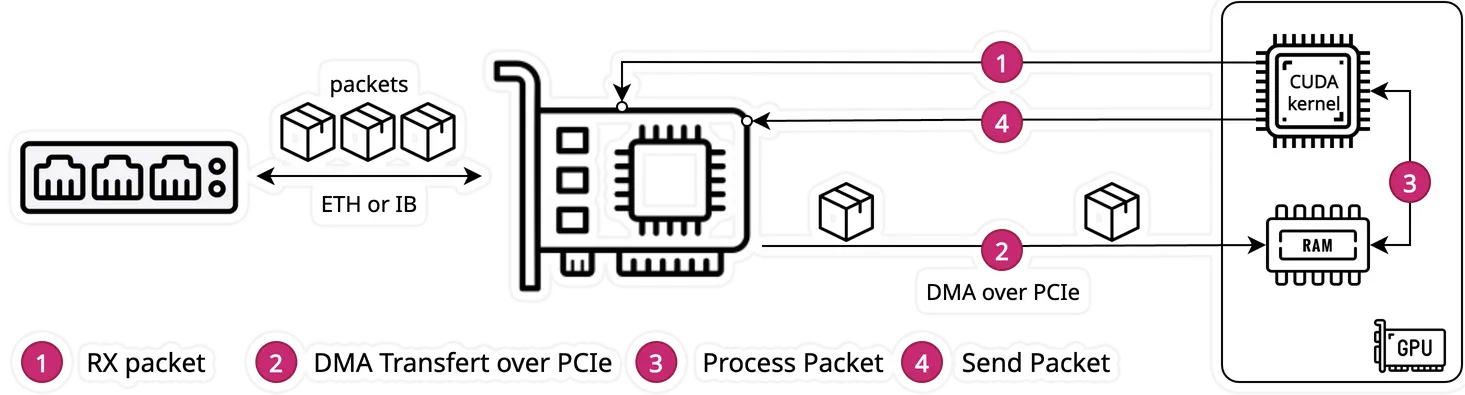
In the above diagram in the GPUNetIO documentation, the “CUDA” box is a bit confusing. I assume it is a kernel running on the GPU, but let’s check what the documentation says:
Traditional approaches often rely on a CPU-centric model, where the CPU coordinates with the NIC to receive packets in GPU memory using GPUDirect RDMA. Afterward, the CPU notifies a CUDA kernel on the GPU to process the packets. …. DOCA GPUNetIO addresses this challenge by offering a GPU-centric solution that removes the CPU from the critical path.
To me, this is still not entirely clear - It states ‘GPU-centric’ for the critical path, but what is the critical path? Are these the steps (1) to (4) mentioned in the diagram? And what is the CPU still needed for? To find the answer, we need to look at the “Async Kernel-Initiated” mode, which is described as the possiblity for “a GPU CUDA kernel to control network communications to send or receive data”. GPUDirect IKA enables:
GPU can control Ethernet communications (Ethernet/IP/UDP/TCP/ICMP)
GPU can control RDMA communications (InfiniBand or RoCE are supported)
CPU intervention is unnecessary in the application critical path
So, this is 100% clear:
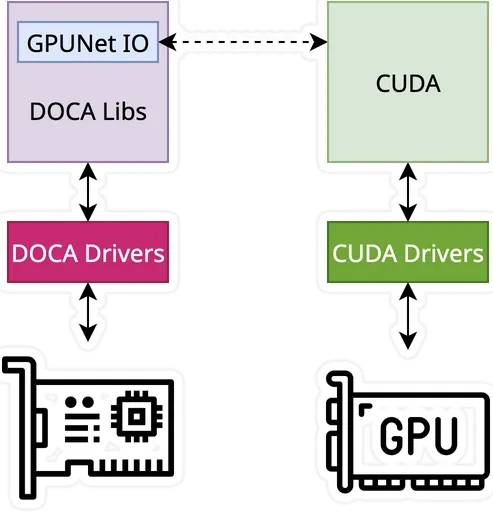
GPU Direct RDMA “eables direct data transfers to / from GPU memory without CPU staging copies.
GPU Direct AKI gives the possibility for the GPU to “control” the Network card.
GPUNetIO is a SW component that handles both GPU Direct RDMA and AKI technologies.
DOCA is the SDK that Nvidia provides to program GPUNetIO enabled HW (among others).
I suppose the confusion arises from the fact that “AKI” should be mentioned as “GPU Direct RDMA + AKI”, as it complements the RDMA capability that allows bypassing the CPU.
RDMA GPU Interconnection Link to heading
We now understand that GPU Direct RDMA, as marketed by Nvidia under the GPUNetIO umbrella, is a Network Card (NIC) based solution, which connects the GPU to the NIC over a PCIe connection. Let’s deep dive into this PCIe connection, abstract the GPUNetIO part, and refocus on the RDMA part:
In the CUDA GPUDirect RDMA official documentation, it says that the only requirement is a PCIe root complex:
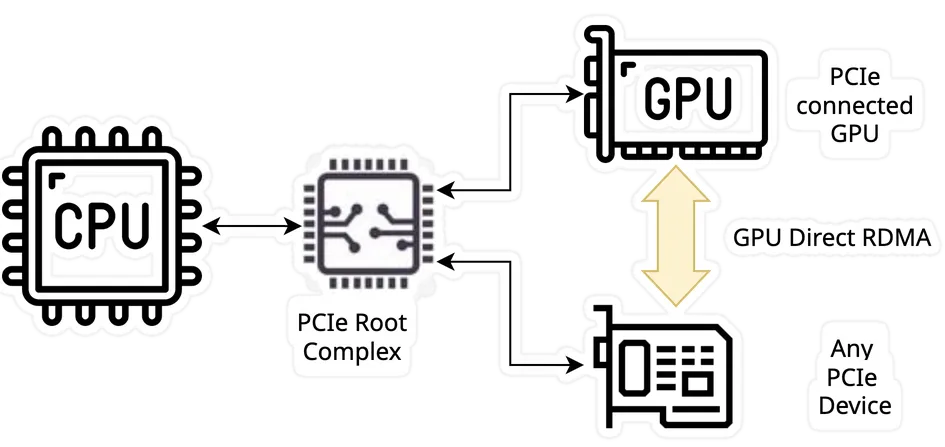
GPUDirect RDMA is a technology introduced in Kepler-class GPUs and CUDA 5.0 that enables a direct path for data exchange between the GPU and a third-party peer device using standard features of PCI Express. …. A number of limitations can apply, the most important being that the two devices must share the same upstream PCI Express root complex.
GPUDirect RDMA is a solution that enables any PCIe device to communicate directly with the GPU, provided it is under the same root complex. So, although mainly “marketed and sold” by Nvidia as a solution where the PCIe device is a network card, it could be any PCIe card, for example, a high-speed camera PCIe card. That’s cool, but let’s try to understand how this would work.
When setting up GPUDirect RDMA communication between two peers, all physical addresses are the same from the PCI Express devices’ point of view. Within this physical address space are linear windows called PCI BARs. Each device has six BAR registers at most, so it can have up to six active 32bit BAR regions. 64bit BARs consume two BAR registers. The PCI Express device issues reads and writes to a peer device’s BAR addresses in the same way that they are issued to system memory.
Traditionally, resources like BAR windows are mapped to user or kernel address space using the CPU’s MMU as memory mapped I/O (MMIO) addresses. However, because current operating systems don’t have sufficient mechanisms for exchanging MMIO regions between drivers, the NVIDIA kernel driver exports functions to perform the necessary address translations and mappings.
What can be confusing here is that the word “DMA” may seem like a better fit compared to “RDMA” when considering an intra-PCIe system that connects heterogeneous devices. But that’s the point. DMA is the solution to transfer data, and RDMA, above it, is the protocol used to give semantics to the data being transferred, using verbs. So, DMA is really only steps (4) and (5) in the diagram below, while the RDMA protocol in the HW on the receive side is only (3).
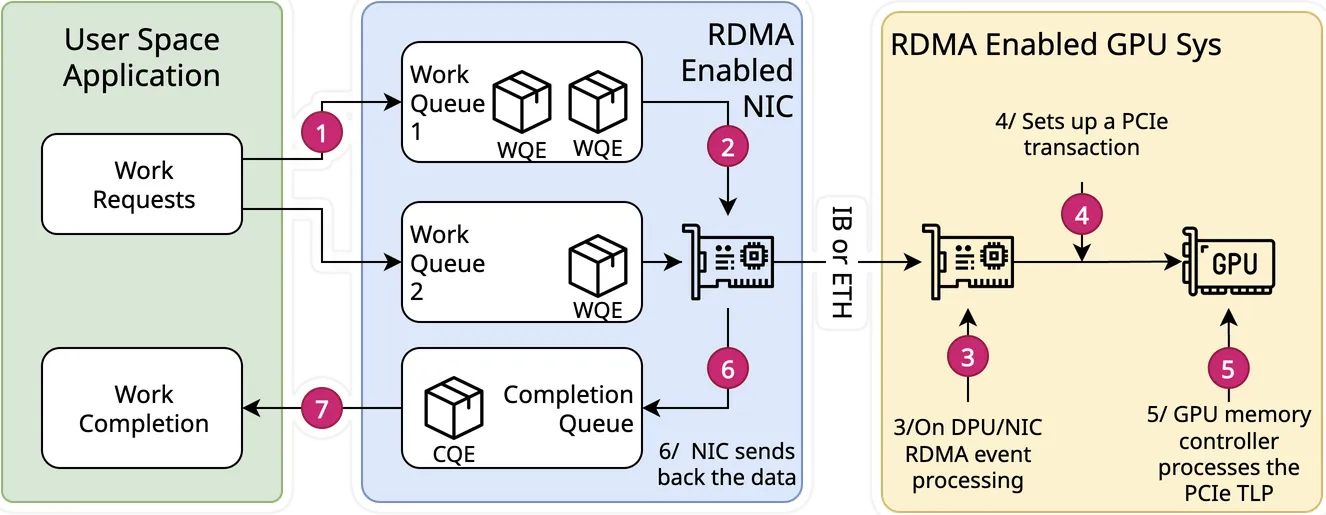
One thing to notice, Nvidia makes it clear that this is not a simple thing, so, to achieve the best performance, it’s probably better to use a known testbed:
Even though the only theoretical requirement for GPUDirect RDMA to work between a third-party device and an NVIDIA GPU is that they share the same root complex, there exist bugs (mostly in chipsets) causing it to perform badly, or not work at all in certain setups.
Transport layer Link to heading
There is still an obvious confusion in the terminology, specifically between Ethernet, InfiniBand, and RoCE: the fact that RoCE is based on Ethernet.

The InfiniBand trade associate describes it in simple terms as an evolution, represented in the above diagram. Note that I have purposely used the name “100G + PFC” instead of the original “DCB” (aka Data Center Bridging) mention. If I understand correctly, DCB is a superset of PFC (aka priority flow control), and the idea is to say that for the DCB/PFC to work, one needs the networking infratructure, including the swithes, to implement those technologies. Otherwise, you fall back to the Ethernet category.
What about NVLink? Link to heading
This memo would not be complete without a reference to NVLink. The immediate question is whether NVlink and InfiniBand are the same or somewhat related. In short, they are complementary, not competing.

NVLink: Fast intra-node communication (within a server, between GPUs).
InfiniBand: Fast inter-node communication (between servers in a cluster)
In the diagram on the right, it is clear that the green arrows are used to interconnect the GPUs between themselves. While the connection between the NICs is InfiniBand.
What is interesting to note is that the NVLink is internal to the Nvidia hardware and not exposed to the outside, unlike InfiniBand connectors, as shown in the diagram below. Note that the Quantum InfiniBand X800 is a beast of power, featuring 800Gb/s links, with co-packaged silicon photonics, but it has nothing to do with Quantum computing.

One last point worth mentioning: Nvidia has introduced NVlink fusion as a way to open the NVLink standard. So, tomorrow, we will probably see custom integration, maybe still requiring a PCB as the “switch” (rather than a cable), but with SoC, which may not be an Nvidia SoC. It is also worth mentioning that AMD has responded to Nvidia’s standard by introducing UALink.
Summary Link to heading
In short, RDMA is not quite complex:

RDMA BAR: as a PCIe BAR mapping: At the physical layer, there is a PCIe device which connects to the GPU via the same PCIe root complex, and maps the memory BAR of all devices.
RDMA NIC: as a HW Network Card (NIC): This PCIe card is usally a network card - but that does not have to be. However, there seems to be only one network card on the market with RDMA capability.
RMDA DPU: as a in-HW Verb Processor: To make the PCIe card RDMA compliant, the HW must be able to process the RDMA verbs directly into the HW, usually using a processor called the DPU.
RDMA Transport: as the transport layer for the network loink: The PCIe device is exposed, on the network side as a transport which can be Ethernet, better Ethernet (RoCev2) and Infiniband.
RDMA Protocol: as the frame format: The protocol used to communicate over the network link is also called RDMA - I did not look at the details of the frame format, but it’s in RFC5040
RDMA Channels: as the way to communicate over QP: The SW / driver / SDK used on the host to communicate to the RDMA device is also called RDMA, but is defined as Queue Paris and Channels.
Voila. I think I understand RDMA a bit better now.
Conclusion Link to heading
Back to the quantum computing challenge - the question is why do even care about RDMA? Well, that’s because Nvdia called their InfinBand switch “Quantum InfiniBand”!
But, yet, despite the fact that their latest Quantum-X800 is a beast, it has nothing to do with Quantum computing. But maybe it could play a key role in interconnecting the Quantum Control to the GPU, for the reinforcement learning challenge?