I am supper happy to be part of the team at Qblox which has been and is still actively working with Nvidia to promote the NVQLink standard, as a way to interconnect heterogenous systems computed on GPUs, CPUs and QPUs (quantum processor, including the upfront quantum controllers which Qblox is developping).

NVQLink at a glance Link to heading
NVQLink is not yet another “cable” to connect GPUs to Quantum processors, but rather a complete framework that allows to interconnect heteregenous devices, from the network to the software stack:
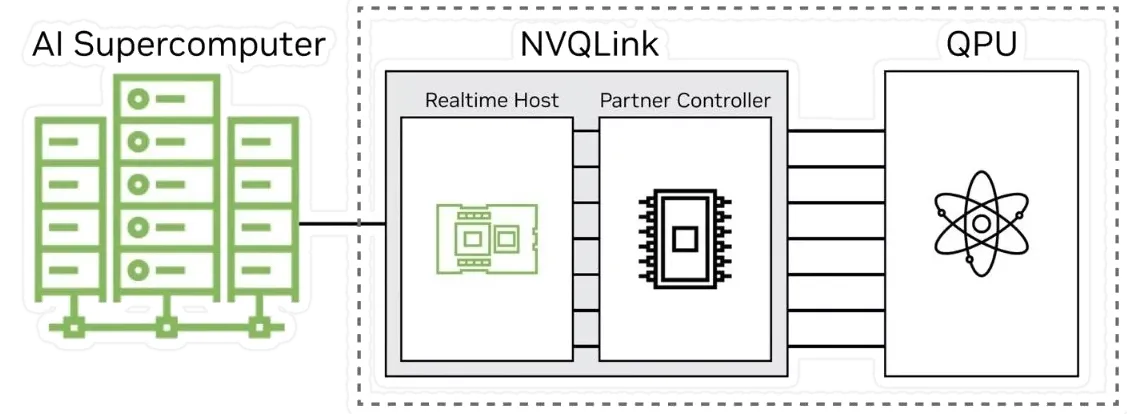 Image credit: Nannod
Image credit: Nannod
What performance spec Link to heading
The key “hardware” specifications emphasize the performance of network & computing resources:
Network throughput: Up to 400 Gb/s from the GPU to the QPU.
Network latency: round-trip latency (FPGA → GPU → FPGA) less than 4.0 microseconds.
GPU HW: Real-time host built on NVIDIA GB200 Grace Blackwell superchips, with a lot of TFLOPS.
Why NVQLink is need Link to heading
You may ask, “Why is this important?”
It creates an open standard to tightly integrate quantum hardware with accelerated GPU compute .
It enables hybrid workflows: Neural network calibration, quantum error correction (QEC), etc.
It provides an open platform that integrates SW and HW as one, allowing anyone to interact with quantum computers, without having to drown in an ocean of knowledge, thanks to Cuda-Q.
NVQLink Specification: Architecture Design Link to heading
The NVQLink white paper is now available from https://arxiv.org/abs/2510.25213, so let’s deep dive into the details of the proposed architecture:
System Architecture Link to heading
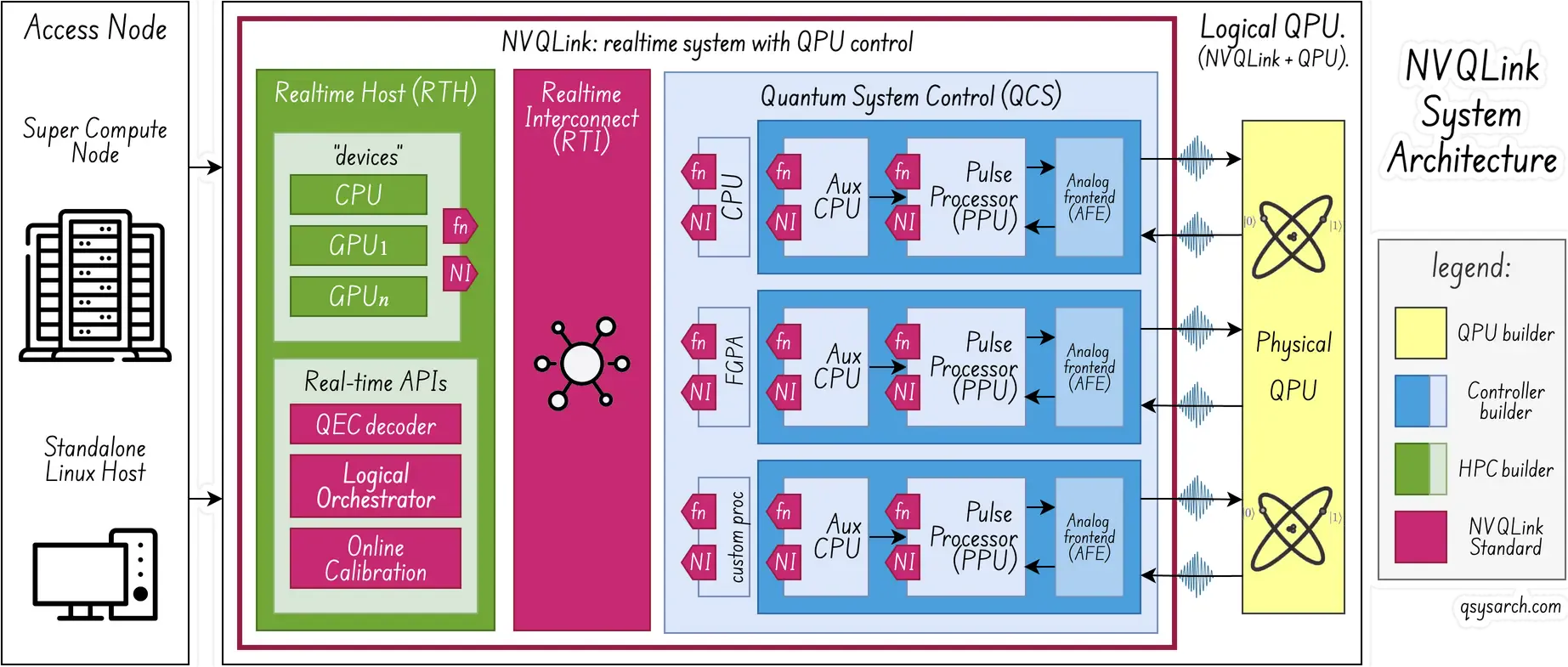 (system diagram adapted from the original picture from the white paper)
(system diagram adapted from the original picture from the white paper)
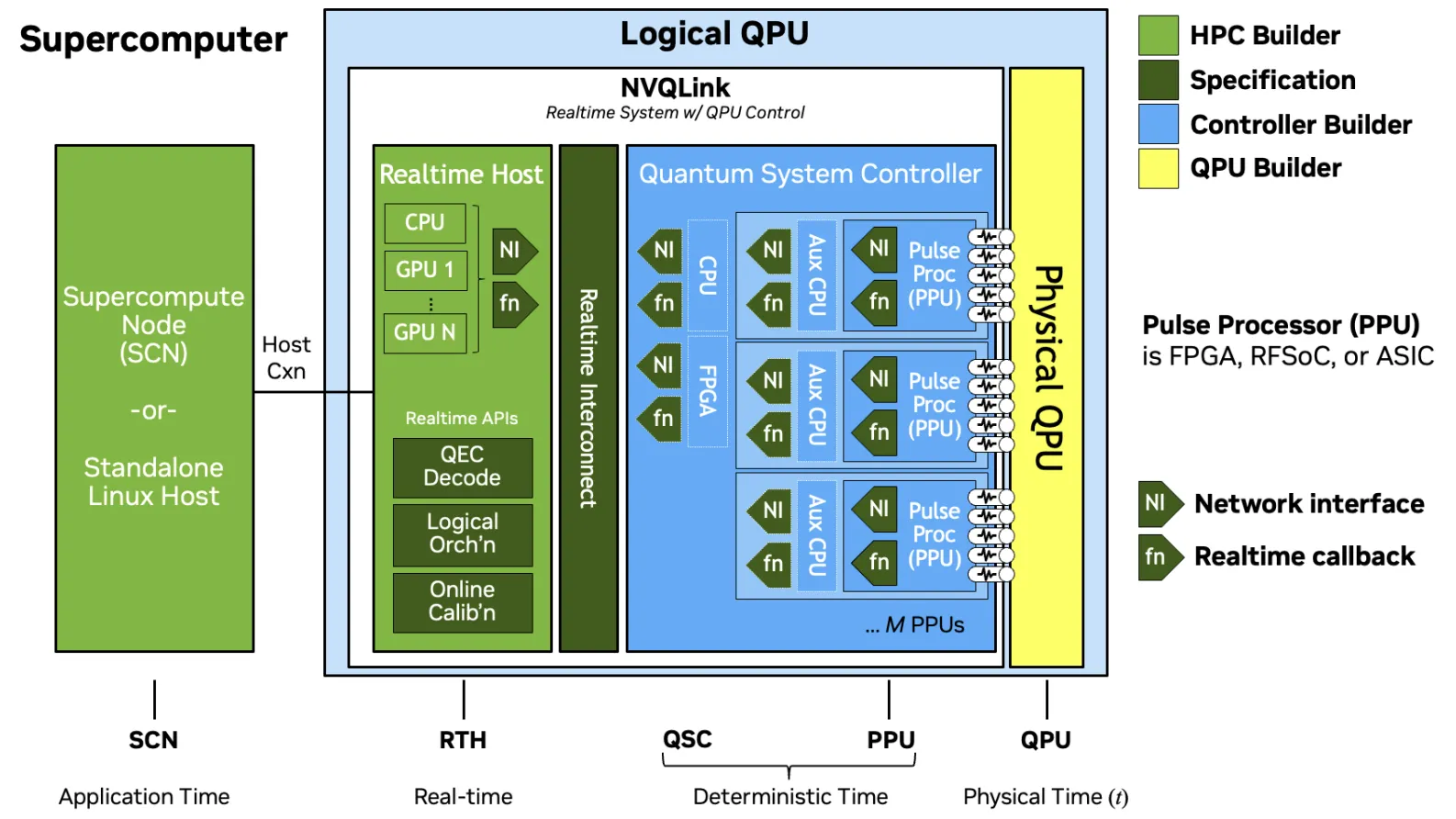
As expected, the details match the high-level overview from Nannod. From a component perspective, the NVQLink architecture comprises the Real-time Host (RTH) and the QPU Control System (QSC). Those two components are connected by a low-latency, scalable real-time Interconnect (RTI). The RTH has traditional HPC compute resources like CPUs and GPUs. As for the QSC, it typically includes the Pulse Processing Units (PPU) that control the QPU.
This diagram introduces two important keywords: fn and NI. In the NVQLink mental model (”programming model”), each of the CPUs, GPUs, PPUs (or other specialized ICs/ FPGA) is referred to as “devices”, and NVQLink makes it possible to remote procedure call (“callbacks” or fn) into any of those devices. This is a highly powerful solution, where NVQLink acts as the glue for the heterogeneous system. The actual implementation of the fn runtime is highly optimized to the point where marshalling is even taken care of. This way, one can ensure latencies of a few microseconds. As for the NI, it stands for Network Interface, and it is conceptualized as a “small” and optional networking card/interface/cable that all parties can use to have a unified, interconnected system.
Time Domains Link to heading
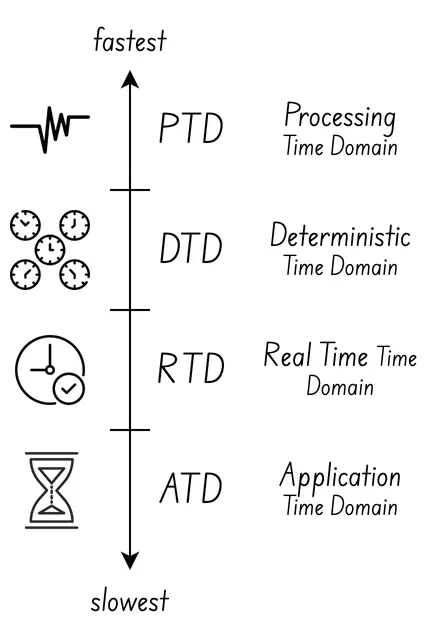
The NVQLink aslo introduces the very important concept of time domains: This is needed because not all of the “processing units” involved in the system are expected to followin the “same clock”.
There are 4 categories of clock, or time domains, from the fastest to the slowest:

Physical Time Domain (PTD): Usually the QPU clock.
Deterministic Time Domain (DTD): Usually the QSC/FPGAs clock, able to operate with quantum-coherent time scales.
Real-time Domain (RTD): Usually in the classic CPU or GPU. Can be within quantum-coherent time, or between two quantum coherent experiements.
Application Time Domain (ATD): Usually the laptop in which jupyter notebook is running!
Network Architecture Link to heading
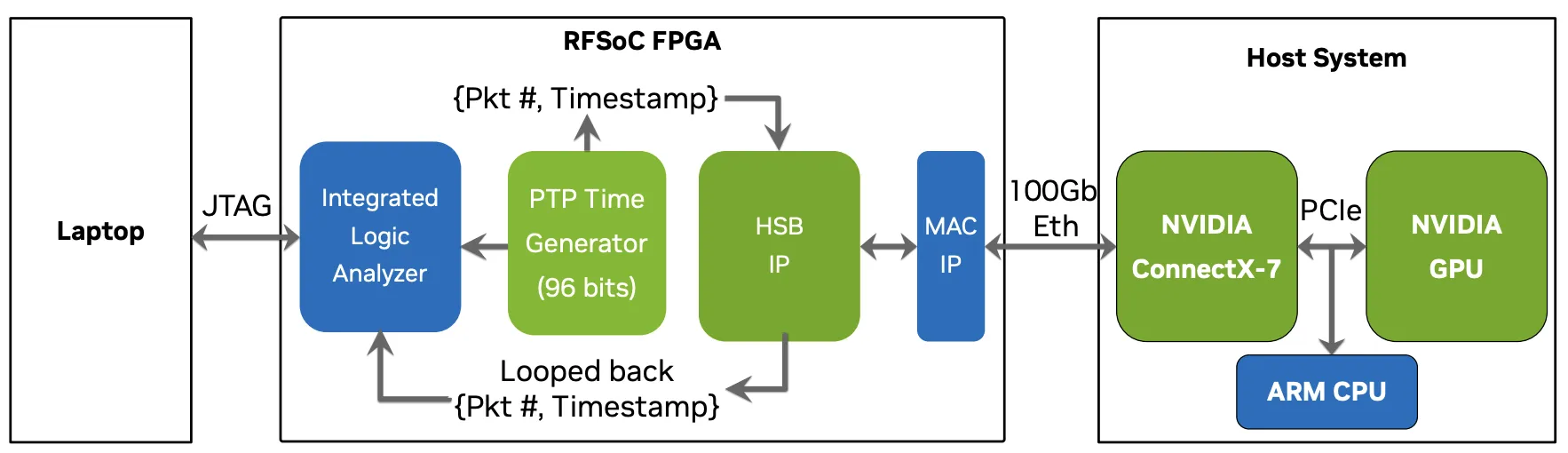
Without any surprise, NVQLink makes use of RDMA and GPUDirect, to bypass any kind of unnecessary CPU processing, and ensure an optimal latency . As written in the specification, “benefiting from these two technologies, only the NIC and GPU are involved during the processing of packets coming from and going to the QSC, without any host involvement”.
The specification also recommends using the “Unreliable Connection” RDMA mode, as the latency price to pay for RCs (Reliable Connections) may be overkill compared to a properly engineered network.
The specification provides a “proof of concept” for the network architecture, as a means to verify the possibly achievable latency. The Holoscan Sensor Bridge module is used, which provides means to send data between an FPGA and NIC using the RDMA over Converged Ethernet (RoCE) protocol, as well as handling the enumeration steps and the control signals. Using this architecture, the spec shows that it is possible to achive a sub-4 microsecond round-trip latency, for a 32 bytes RDMA payload, equivalent to 92 bytes ethernet frame.
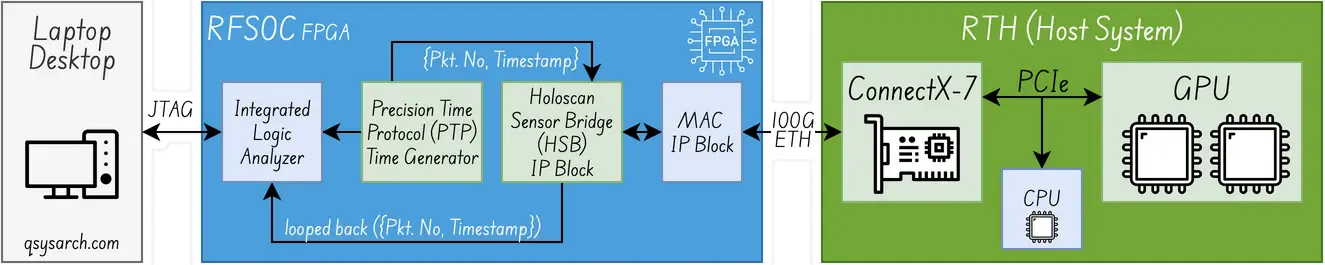 (diagram adapted from the original picture from the white paper)
(diagram adapted from the original picture from the white paper)
Compilation Architecture (aka CudaQ+NVQLink programming model) Link to heading
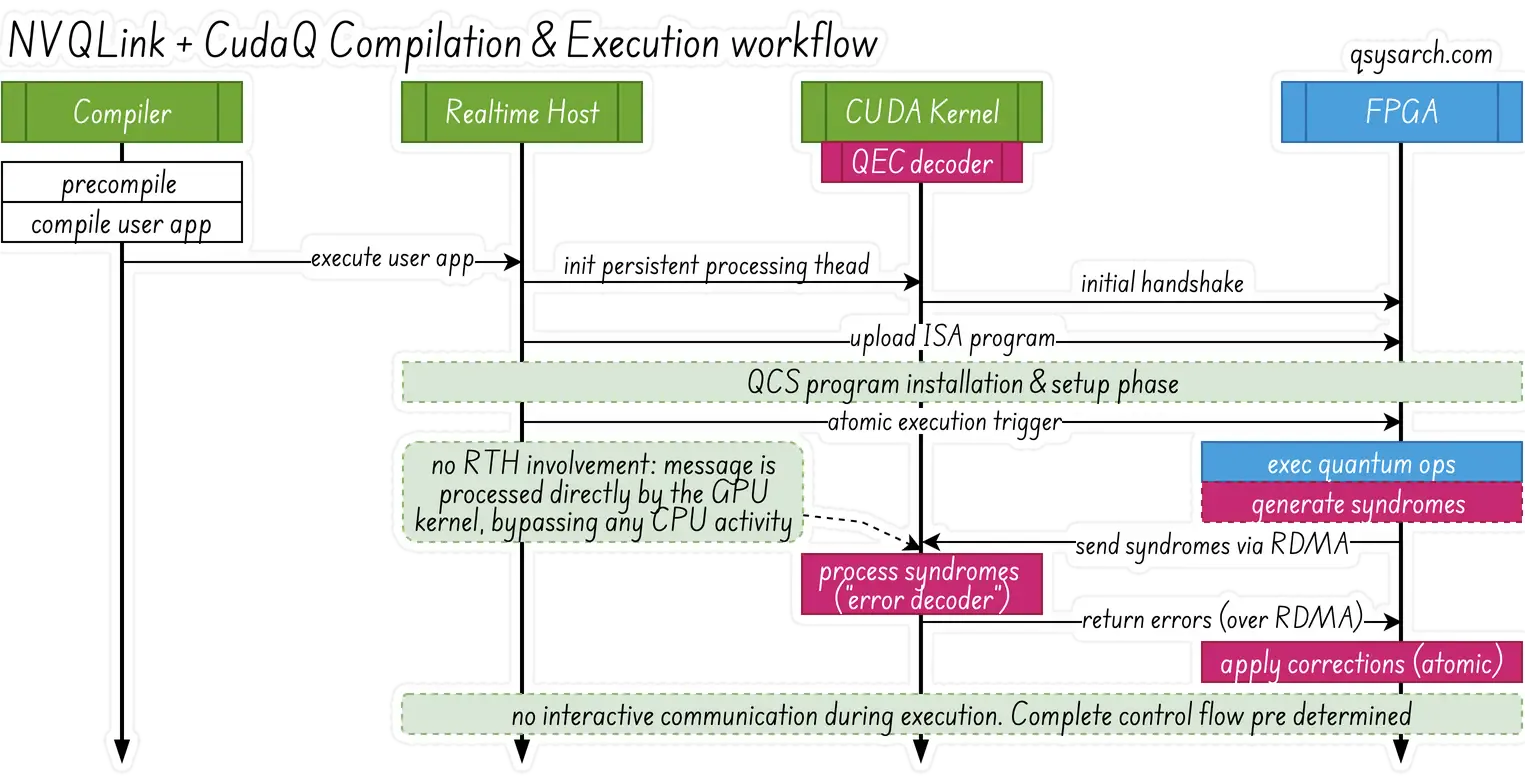
NVQLink distinguishes between slow and fast modalities, and I will specifically examine the impact of fast modality architecture in this section (so-called “High Latency Sensitivity”). The main difference with slow modalities is that the architecture allows for Just-in-Time compilation (JIT) as well as possible RTH mediation during execution.
For CudaQ + NVQLink to work with fast modalities, the specification stipulates that the complete ISA programs must be uploaded to FPGAs in advance and triggered atomically, with minimal interactive communication with the Real-time Host during execution. JIT is really a cool piece of technology, so it’s a pity it can’t be used for fast modalities. However, the specification makes it clear that the FPGAs are allowed to “receive” dynamic updates from the RTH (”via an instruction queue”), provided that the instruction queue remains non-empty until program termination. That sounds like “just in time” scheduling.
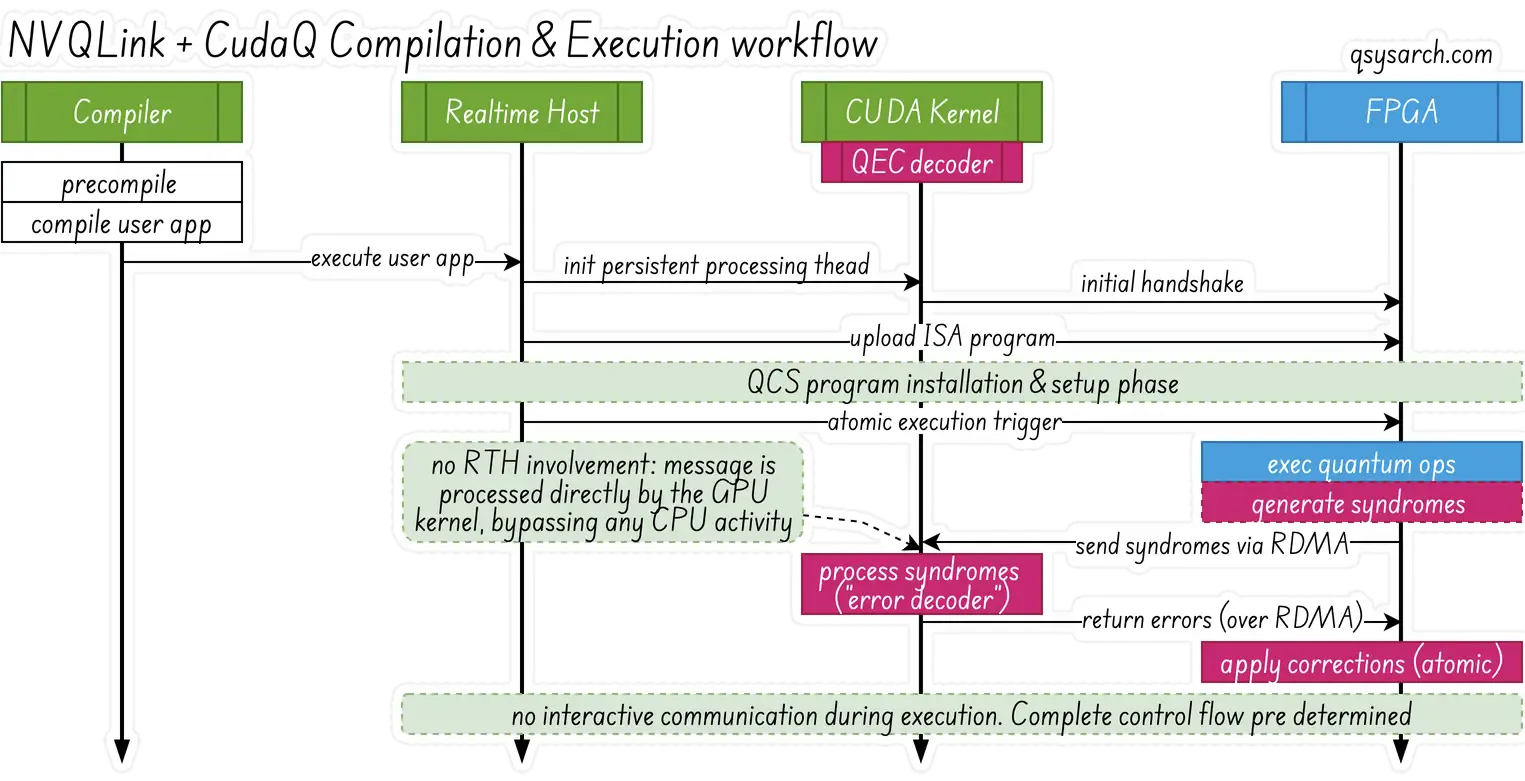
Without any surprise, the specification makes it clear that the compilation must perform aggressive ahead-of-time optimizations - and this is definitely something that all quantum control stack vendors do at heart. It is also mentioned that if any callback needs to be executed in the GPU, the CUDA kernel in the GPU must be preinitialized and actively waiting for events - nothing special here, this is the standard DOCA GPUNetIO workflow
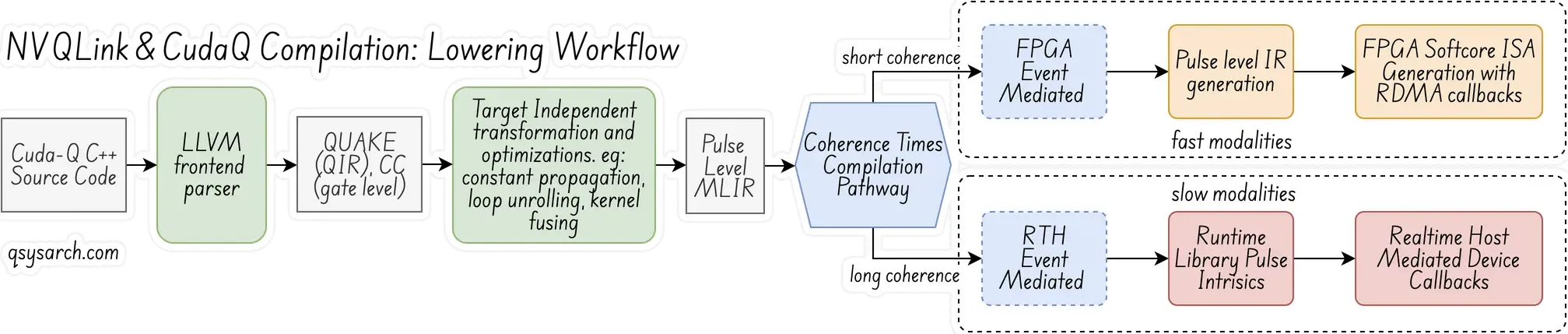
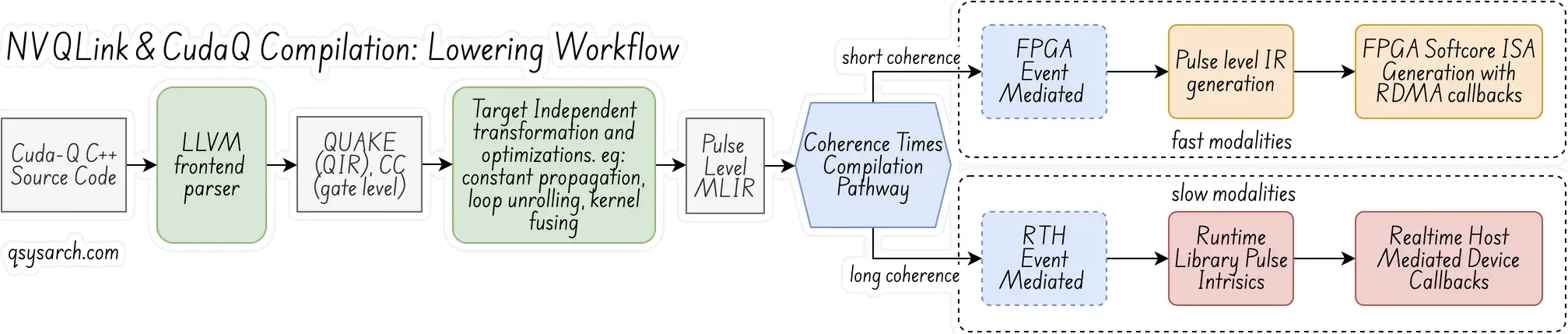
The CUDA=Q compilation and lowering workflow to the NVQLink architecture is based on the standard LLVM MLIR architecture (see diagram above). The first step is to parse the CUDA kernels and generate the Quantum IR (also known as QIR, or QUAKE) and CC (classic compute) intermediate IRs, which are abstracted at the gate level. A later phase introduces the necessary optimization and kernel fusion, producing a pulse-level dialect. Then, depending on the modality type, the next lowering phase utilizes either the RTH or FPGA mediation.
The “quantum kernel” is identified by the __qpu__ prefix.
int gpu_adder(int, int); // This function is executed on GPU
__qpu__ int simple_quantum_kernel(int i) { // This function (kernel) is executed on the QCU
cudaq::qubit q;
h(q); // Operate an H gate on qubit q
auto readout = mz(q); // Read the Z axis of qubit q
return cudaq::device_call(2, gpu_adder, i, readout); // This is tail function call
}During the compilation phase, it is first converted (“lowered”) to a mix of QUAKE (Quantum dialect) and CC (Classical Compute dialect) intermediate representations (IR), or dialects:
func.func @simple_quantum_kernel(%arg0: i32) -> i32 {
%0 = quake.null_wire
%1 = quake.h %0 : (!quake.wire) -> !quake.wire
%measOut, %wires = quake.mz %1 : (!quake.wire) -> (!quake.measure, !quake.wire)
%2 = quake.discriminate %measOut : (!quake.measure) -> i1
%3 = cc.cast unsigned %2 : (i1) -> i32
%4 = cc.device_call @gpu_adder on 2 (%arg0, %3) : (i32, i32) -> i32
return %4 : i32
}Runtime Architecture: meta programming with traits Link to heading
In line with the concept of zero-copy deeply rooted in RDMA, the NVQLINK runtime also promotes high performance and zero-overhead abstraction, achieved with two key essential concepts:
- trait-based composition: It is a compile time means to expressing any device behavior, and NVQLink proposes a set of standard traits.
- static polymorphism: It is a compile time means for the compiler to instanciate the right method wihtout need for virtual table indirection.
There are 4 essential traits:
- explicit_data_marshalling_trait: means to allocate, and transfer data accross the system.
- device_callback_trait: means to invoke device functions (“RPC”)
- quantum_control_trait: means to upload and start program on the QCS
- rdma_trait: means to efficiently initialze structure from raw memory buffer.
In practice, the traits utilize the C++ language to a super-advanced level. This is for example the data marshaling trait.
template <typename Derived> class explicit_data_marshaling_trait {
public:
void *resolve_pointer(device_ptr &devPtr);
device_ptr malloc(size_t size) const;
template <typename... Sizes, enable_if_t<(conjunction_v<is_integral<Sizes>...>),int> = 0>
auto malloc(Sizes... szs) { return make_tuple(static_cast<Derived *>(this)->malloc(szs)...); }
void free(device_ptr &d);
template <typename... Ptrs, typename = enable_if_t<(conjunction_v<is_same< remove_cv_t<remove_reference_t<Ptrs>>, device_ptr>...>)>>
void free(Ptrs &&...d) { (free(d), ...);
}
void send(device_ptr &dest, const void *src);
void recv(void *dest, const device_ptr &src);
};There is a lot to unpack in this syntax, which is IMO even more powerful than the Rust syntax (eg, cow). This syntax is also known as metaprogramming, and in the context of NVQLINQ, it refers to compile-time, or static, polymorphism. Let’s have a look at the line template <typename… Sizes, enable_if_t<(conjunction_v<is_integral
is_integral<Sizes>as α:trueifSizesis an integral type i.e. int,float,bool, etc…conjunction_v<α...>as β:trueif all the values inα...are trueenable_if_t<(β),int>as δ: a group 2 conditional that should fail ifβwas false.template <typename... Sizes, δ = 0>: A SFINAE construct that preventsδfrom failing.
With this syntax, it becomes possible to have a specialized malloc of multiple blocks at once:
class gemm_device : public explicit_data_marshalling_trait { ... }
gemm_device gpu_gemm; // "gemm" stands for general matrix multiply
auto [column, row, matrix] = device.malloc(1024, 1024, 1024*1024);You may ask why this matters. It is as simple as giving the possibility of having optimal specialization at compile time. In this case, the implementation of malloc can bundle the memory buffer contiguously, making it suitable for RDMA exchanges and for atomic marshalling of multiple datums. Cool, isn’t it?
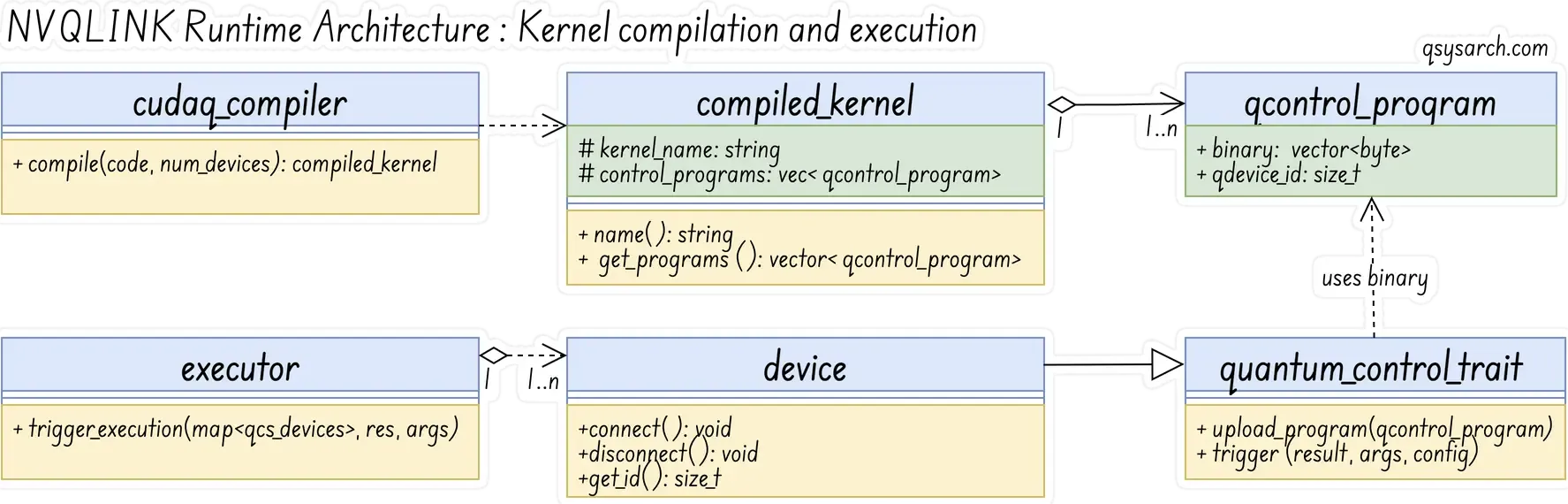
Runtime Architecture: kernels Link to heading
NVQLink provides a set of standard interfaces for compiling, uploading, and executing (triggering) quantum kernels. Since one picture is better than one thousand words, I will summarize this section with this drawing:
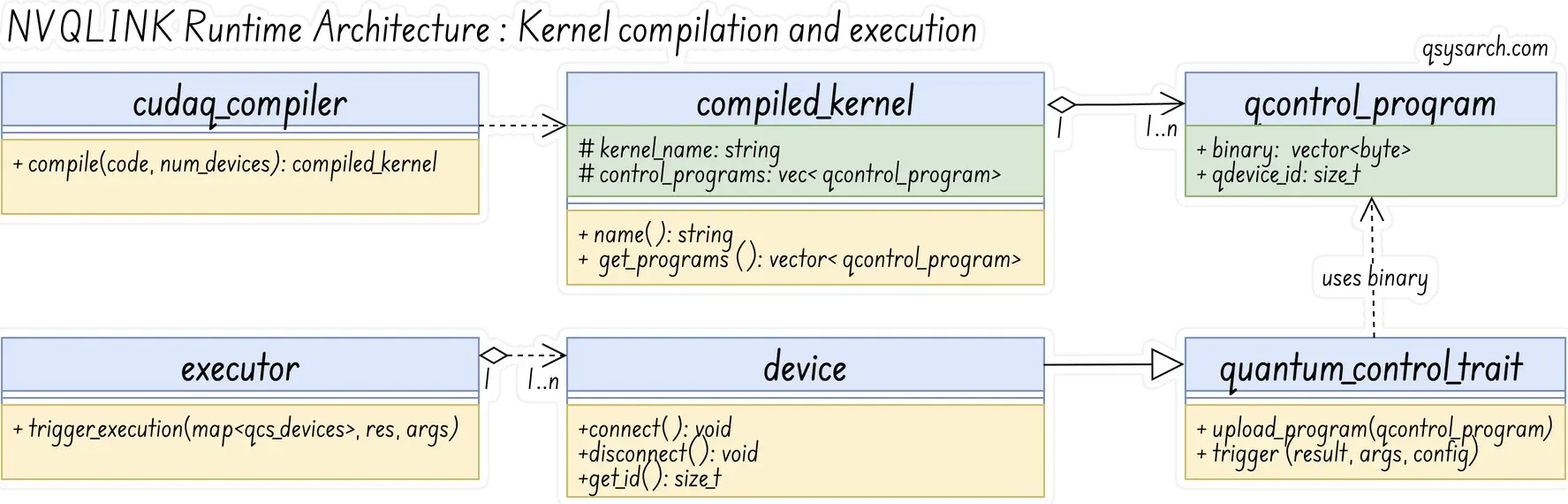
One thing to notice is that a QCS (Quantum Control System) is composed of multiple PPUs (Pulse Processor Units). Therefore, when compiling a kernel, it may need to be executed co-synchronously on multiple PPUs. (Note that NVQLink is agnostic to co-synchronicity, but each QCS vendor has its own solution, such as SYNQ for Qblox).
In the context of the NVQLINK interfaces, the concept of PPUs is abstracted away and replaced by the QCS, which stands for a generic quantum device. So, when compiling a kernel, NVQLINK generates multiple programs for each of the QCS.
Runtime Architecture: Higher level abstraction “library” Link to heading
Since the code explained in the previous section can be quite complex to comprehend and build upon, NVQLINK provides a set of higher-level APIs, in the form of functions:
The library contains functions to cope with basic initialization and shutdown functions, to cope with device-specific data mutation API, such as memcpy, to move data to and from the Logical QPU, to cope with upload and execution. Below is a simplified version of those functions:
void initialize(DeviceTypes &&...in_devices);
void shutdown();
device_ptr malloc(size_t size, size_t devId);
void free(device_ptr &d);
void memcpy_to_qpu(device_ptr &arg, const void *src);
void memcpy_from_qpu(void *dest, const device_ptr &src);
handle load_kernel(const string &code, const string &kernel_name);
void launch_kernel(handle kernelHandle, device_ptr &result, const vector<device_ptr> &args);Application Example: Let’s teleport Link to heading
to be completed
Conclusion Link to heading
NVQLINK is a powerful system-level abstraction that enables the interconnection of heterogeneous systems with a highly efficient and optimized runtime. What makes it more attractive than any other framework is that the NVQLink system is composed of standard stacks, including RDMA for the network, LLVM for the compiler, and traits and standardized APIs for the runtime.
With NVQLINK, developers and integrators no longer need to worry about interconnection. Instead, they can focus on composing their heterogeneous system and compile their multi-device kernels within a single framework, and let the NVQLINK runtime orchestrate the execution of the different “devices”, just like if it was one system. The NVQLink runtime takes care of the networking, marshalling and inter-devide calls, so that you do not have to.
This is a huge leap— together with CudaQ, it will enable quantum engineers to create powerful apps, just as Nvidia CUDA enabled powerful Neural Network applications. Think LLM with a bit of Quantumness…
Prompt: draw an image of a “Large Qubits Model” which is compute on an adjacent GPU connected via the NVQLINK system
ChatGPT did not get it that NVLINK is not NVQLINK.
Prompt: Can you draw a cartoon style image of an NVQLINK system, interconnecting a “Large Qubit Model” connected to an adjacent GPU.
ChatGPT still does not get it that NVQLINK is not a “cable”, but a system level framework that makes it possible to compose kernels that are executed on multiple heterogenous devices. And that the cable is expected, for now, to be an RDMA (because it is a standard), but could also well be NVLink in 5 years.
References
- Platform Architecture for Tight Coupling of High-Performance Computing with Quantum Processors
- An LLVM-based C++ Compiler Toolchain for Variational Hybrid Quantum-Classical Algorithms and Quantum Accelerators
DrawIO diagrams used in this memo:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
In the press Link to heading
QPU Vendor Link to heading
- Pasqal: Integrated with their Qadence/Pulser stack.
- Quandela: Integrated with the Merlin framework
- IQM: Together with Zurich Instruments.
- Infleqtion: Integrated with the Superstaq.
- OQC|Oxford Quantum Circuits:
- Orca Computing: PT-Series systems
- Rigetti
- Silicon Quantum Computing:
- SEEQC:
- Alice & Bob
- Quantinuum
- IonQ