This memo returns to GPU basics. It focuses on the core deep learning operation: matrix multiplication. First, I will describe the basic and academic implementation. Then, I will look at the optimisations needed to use the GPU efficiently.
Understanding the naive matrix multiplier Link to heading
Let’s start with this basic example that you often find in textbooks.
/**
* Kernel to perform matrix multiplication C = A × B
* A is of size N x M, B is M x N, and C is N x N
* Each thread computes one element of matrix C.
*/
__global__ void naive_matrix_multiply(float* A, float* B, float* C) {
// Calculate global row and column for this thread
int row = blockIdx.y /* 0...16 */ * blockDim.y + threadIdx.y;
int col = blockIdx.x /* 0...16 */ * blockDim.x + threadIdx.x;
if (row < N && col < N) {
float sum = 0.0f;
for (int k = 0; k < M; k++) {
// C[row][col] = sum(A[row][i] * B[i][col])
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
}At first glance, this seems easy. You just compute each cell of the output matrix C. This kernel code appears to get the job done. Here is a more visual representation of the kernel.
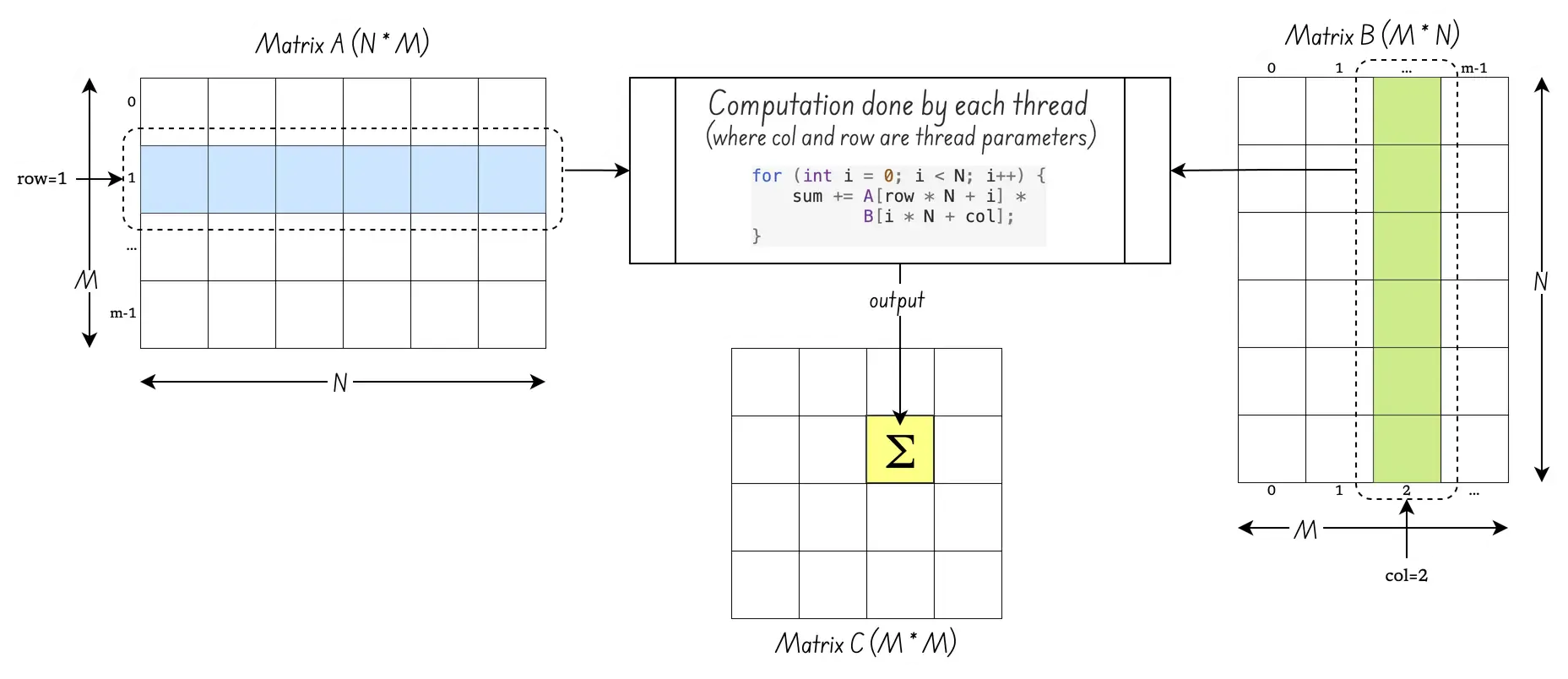
The reality is a bit more complex. How do you make sense of blockIdx, blockDim, and threadIdx? To understand that, go back to how GPUs are organised around threads, warps, and streaming multiprocessors. Here is an opinianated representation of the H100 “Hopper” GPU microarchitecture from Nvidia:
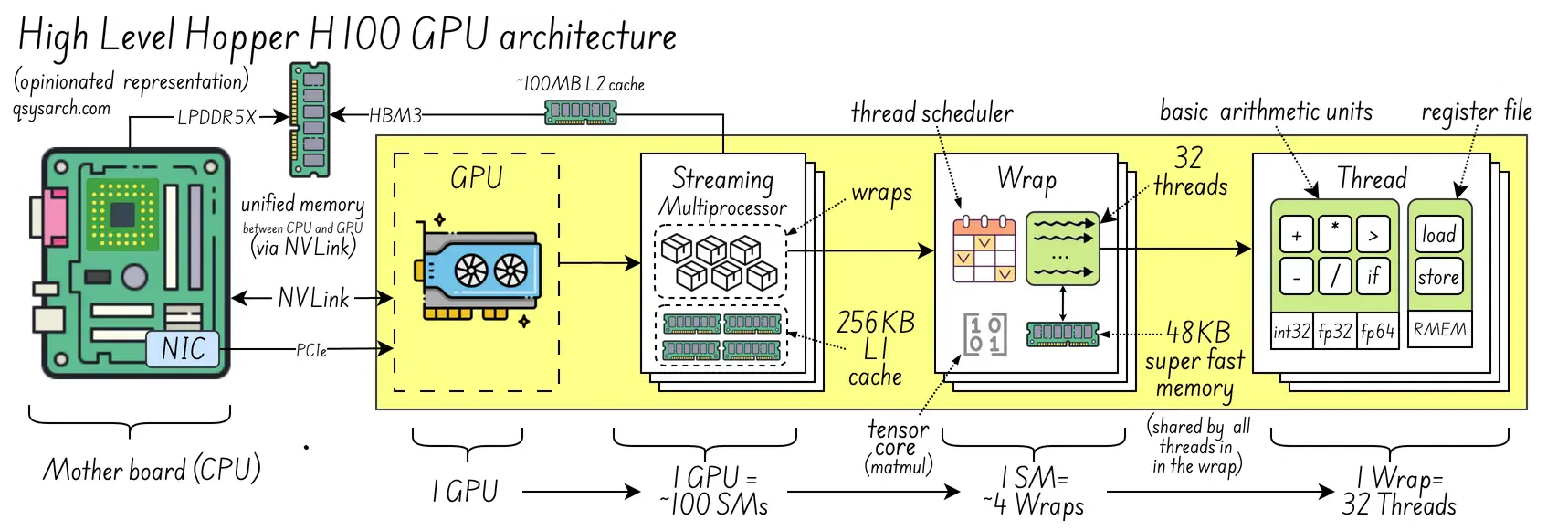
At a high level:
1 Streaming Multiprocessors = 4 ~ 64 Wraps
1 Wrap = 32 ~ 64 Threads
But, so, how is the code fragment that computes sum associated with a thread, warp, or even streaming multiprocessor? Where are the allocation and mapping decisions made? First, we need to understand how the kernel is configured:
int launch_kernel(float *d_A, *d_B, *d_C) {
dim3 block_size(16, 16); // 16x16 threads per block -> 256 threads
dim3 grid_size(4, 4); // 4x4 blocks per grid = 64 blocks
// 2. Launch the kernel with the specified dimensions
naive_matrix_multiply<<<grid_size, block_size>>>(d_A, d_B, d_C);
}With this configuration, you could multiply a matrix with size N of 16*4 = 64. What if N was 1000? In that case, set the block size to (1000+15)/16. Does that mean blocks are allocated to warps? What if the number of threads in the block is bigger than the number of hardware threads?
Well, this is where the GPU scheduling needs to be introduced. At a glance, if there are more threads needed than there are threads on the physical hardware, then the GPU will allocate several warps:
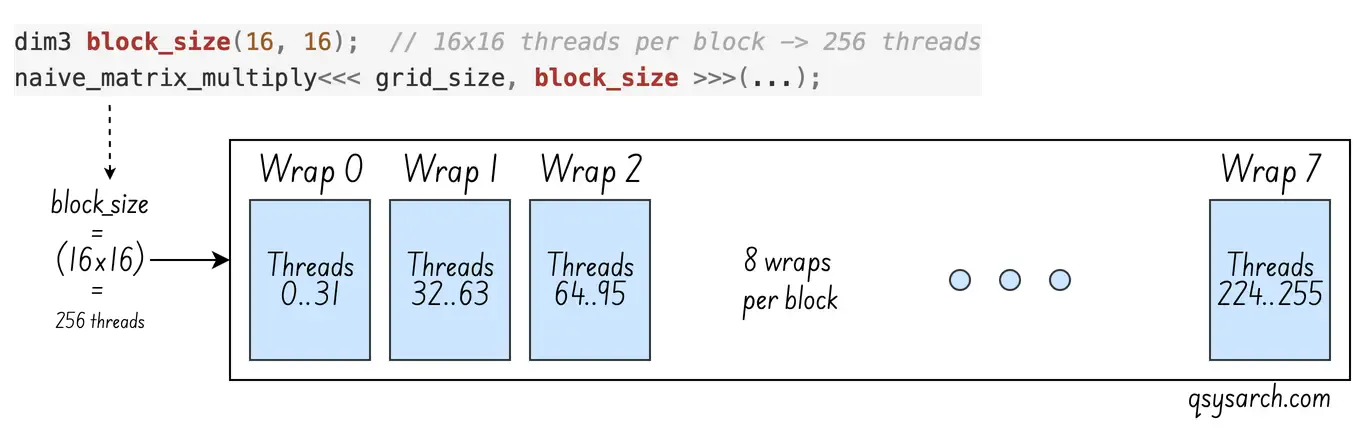
The next question is how the 8 warps needed per block are associated with the streaming multiprocessor, especially when a streaming multiprocessor has fewer warps than a block requires. The answer is fantastic: a streaming multiprocessor can have more than 4 warps, which it schedules in alternation: whenever a warp stalls due to a memory access, the streaming multiprocessor immediately switches to another warp. This is called latency hiding, and it’s the fundamental GPU performance strategy. Without this, the efficiency would not be that high.
Now consider grid_size. Is grid_size mapped directly to hardware resources? It is not. The grid is just a logical concept. It ensures enough blocks are available to cover the matrix. grid_size does not correspond to hardware. Blocks are allocated to each SM at run-time from a queue.
The allocation is based on the resources needed by the block (each wraps has a limited number of registers, and it needs to make sure that each block has its own set of registers statically allocated.
When a block has finished its computation, the SM pulls a new block from the scheduler queue to replace the completed one. Once assigned, the block is pinned to that SM, and its registers are allocated for execution.
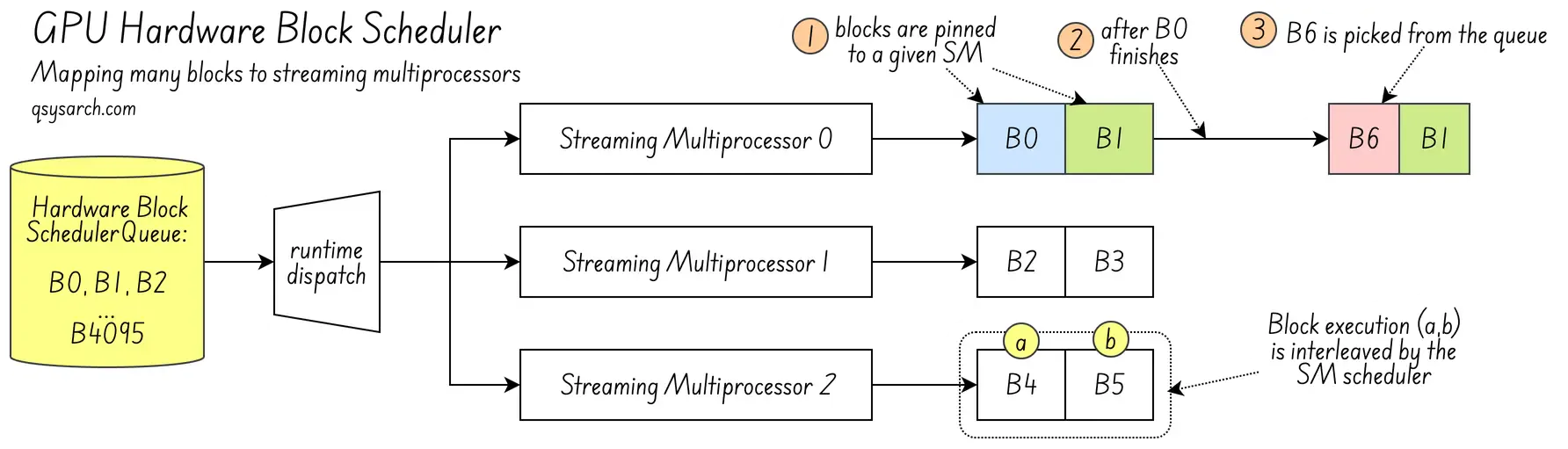
One last question: Are blocks pinned to SM or to warp? Is memory used by threads in the block allocated in the warp? If not, the SM would need to move memory between warps. Yes, within the SM, warps of a block are pinned. If block 0 is allocated to warp 0, and block 1 to warp 1, this will always be the case.
Improving the naive matrix multiplier Link to heading
Now that we understand concurrent thread execution, consider the naive matrix multiplication kernel. All threads compete for memory access to matrices A and B. Every thread streams an entire row of A and a column of B from global memory. There is no reuse. B is accessed column-wise (B[i * N + col]), so burst access and memory caching can’t be used effectively.
The simplest answer is to use shared memory. First, load part of the matrix into the warp memory as a tile of size T*T. Then, let threads read only from this local memory. This way, threads don’t compete for memory access. Using warp interleaving, the SM ensures that while one warp loads memory into the cache, the other warp computes the sum. Here is the enhanced kernel:
__global__ void matmul_tiled(float* A, float* B, float* C) {
__shared__ float A_shared[T][T];
__shared__ float B_shared[T][T];
int tx = threadIdx.x, ty = threadIdx.y;
int row = blockIdx.y * T + ty; // global row in C
int col = blockIdx.x * T + tx; // global col in C
float accumulator = 0.0f;
for (int t = 0; t < M; t += T) {
// Read [T,T] subtile from matrix A and B.
// Assume that M and N are multiples of T (no bound check)
A_shared[ty][tx] = A[row * M + t + tx];
B_shared[tx][ty] = B[(t + ty) * N + col];
__syncthreads(); // wait all threads to finish loading
for (int k = 0; k < TILE; ++k)
accumulator += A_shared[ty][k] * B_shared[k][tx];
__syncthreads(); // all threads are ready to load again
}
C[row * N + col] = accumulator;
}For the sake of simplicity, I assume that M and N are multiples of T, so there is no bound checking when loading the global matrix into the A_shared and B_shared
There is a bit of magic in this code. All threads in the block execute the same memory read: A[row * M + t + tx]. Since t is contiguous, threads read from the same memory region. This enables memory burst and caching. The first thread initiates the burst read. Other threads use the cache populated by that burst. B is not transposed, so the trick does not work for B. Also, __syncthreads() synchronises threads within a block, ensuring they run on the same SM.
With the prior naive multiplier, the block size was arbitrary. With the tiled approach, the block size must fit the tile size T*T, as the diagram shows:

The tiled approach lets blocks load while others compute. In this case, computation may be light and take less time than memory loading. To solve this, increase the work per thread during computation. Each thread can compute a 2x2 element set instead of just one. With K=2, and T a multiple of K, this is possible.
_global__ void matmul_tiled_and_coarsened(float* A, float* B, float* C) {
__shared__ float A_shared[T][T];
__shared__ float B_shared[T][T];
int tx = threadIdx.x, ty = threadIdx.y;
int rowBase = blockIdx.y * T * K + ty;
int colBase = blockIdx.x * T * K + tx;
float accumulators[K][K]; // That's register memory
for (int t = 0; t < M; t += TILE) {
A_shared[ty][tx] = A[row * M + t + tx];
B_shared[tx][ty] = B[(t + ty) * N + col];
__syncthreads();
for (int k = 0; k < TILE; ++k)
for (int wr = 0; wr < K; ++wr)
for (int wc = 0; wc < K; ++wc)
acc[wr][wc] += A_shared[ty + wr * (T/K)][k] * B_shared[k][tx + wc * (T/K)];
__syncthreads();
}
// Write out the T×T accumulated result
for (int wr = 0; wr < T; ++wr)
for (int wc = 0; wc < T; ++wc) {
int r = rowBase + wr * (T/K);
int c = colBase + wc * (T/K);
C[r * N + c] = acc[wr][wc];
}
}Conclusion Link to heading
Voila. This is basically how a GEMM (General Matrix Multiplication) unit works!
Next, I should introduce special hardware like Tensor Core (NVIDIA) or Matrix Fused Multiply-Add (AMD). These are specialized units in the streaming multiprocessor that compute the T*T*K accumulated multiplications. I’ll save this for a later memo!
References:
- The icons used in this memo are from Icons8
- eunomia.dev: cuda tutorial
- Inside NVIDIA GPUs: Anatomy of high performance matmul kernels
- CUDA – Threads, Blocks, Grids and Synchronization
DrawIO diagrams used in this memo:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}