xPU: It is an umbrella term for a specialised Processing Unit (PU), where “x” can represent any computing architecture customised for a specific workload. Common variations include GPUs (graphics), TPUs (tensor/AI), NPUs (neural), DPUs (data), or PPUs (pulse, mainly used for quantum control stacks).
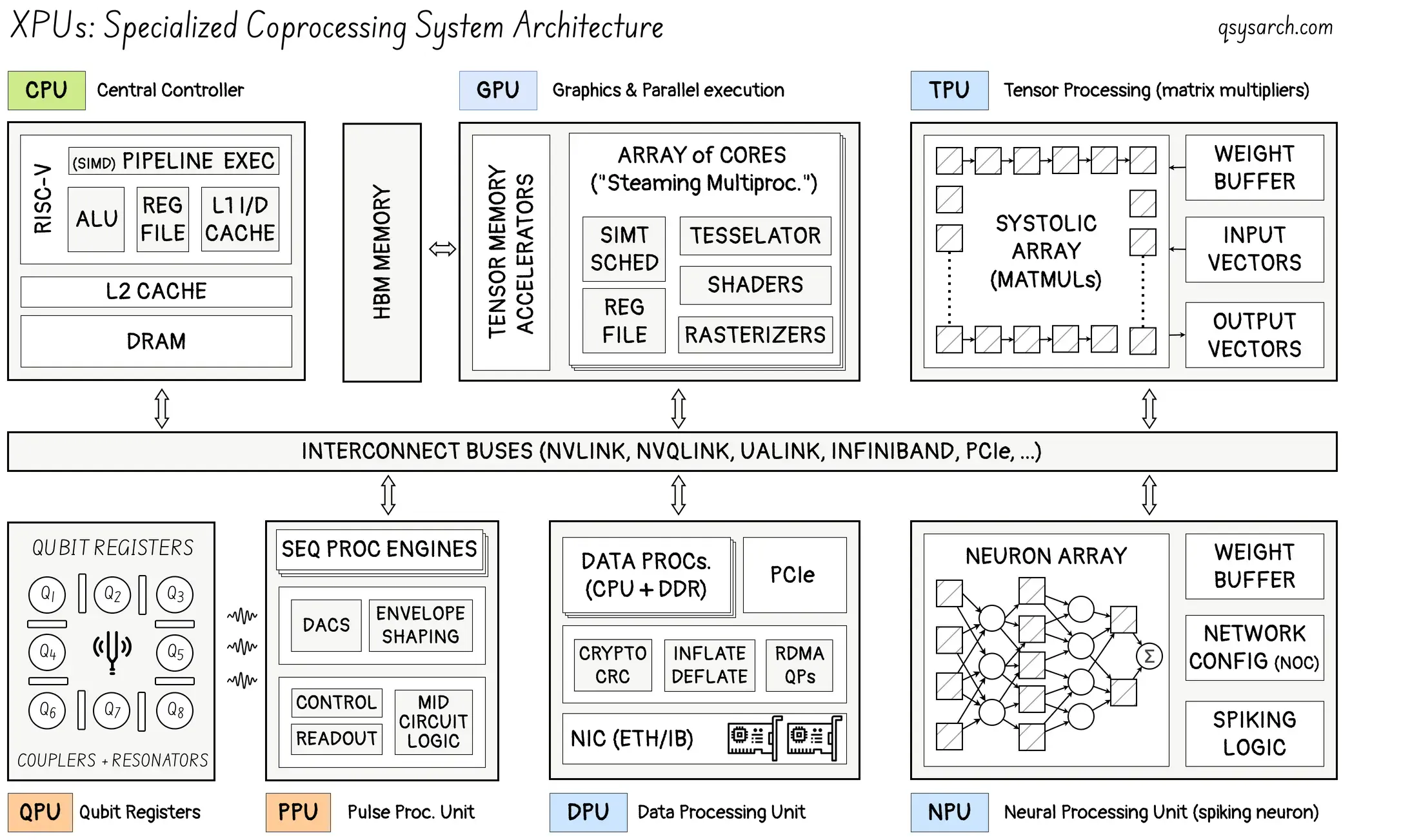
This super-short memo aims to provide insights into the xPU market landscape as applied to AI inference.
Market Landscape Link to heading
When looking at the market landscape for AI inference Asic, the most useful axis may not be raw performance but whether a vendor’s differentiation is defensible over a 3–5 year horizon. From this angle, Three clusters emerge:
- The universal platform: NVIDIA and the vertical integrators: AMD, Google
- the current challengers Groq, Cerebras, FuriosaAI, Positron, SambaNova
- The future challenges: Extropic, Normal Computing, Unconvential, Mottronix, Akhetonics

Universal Platform Link to heading
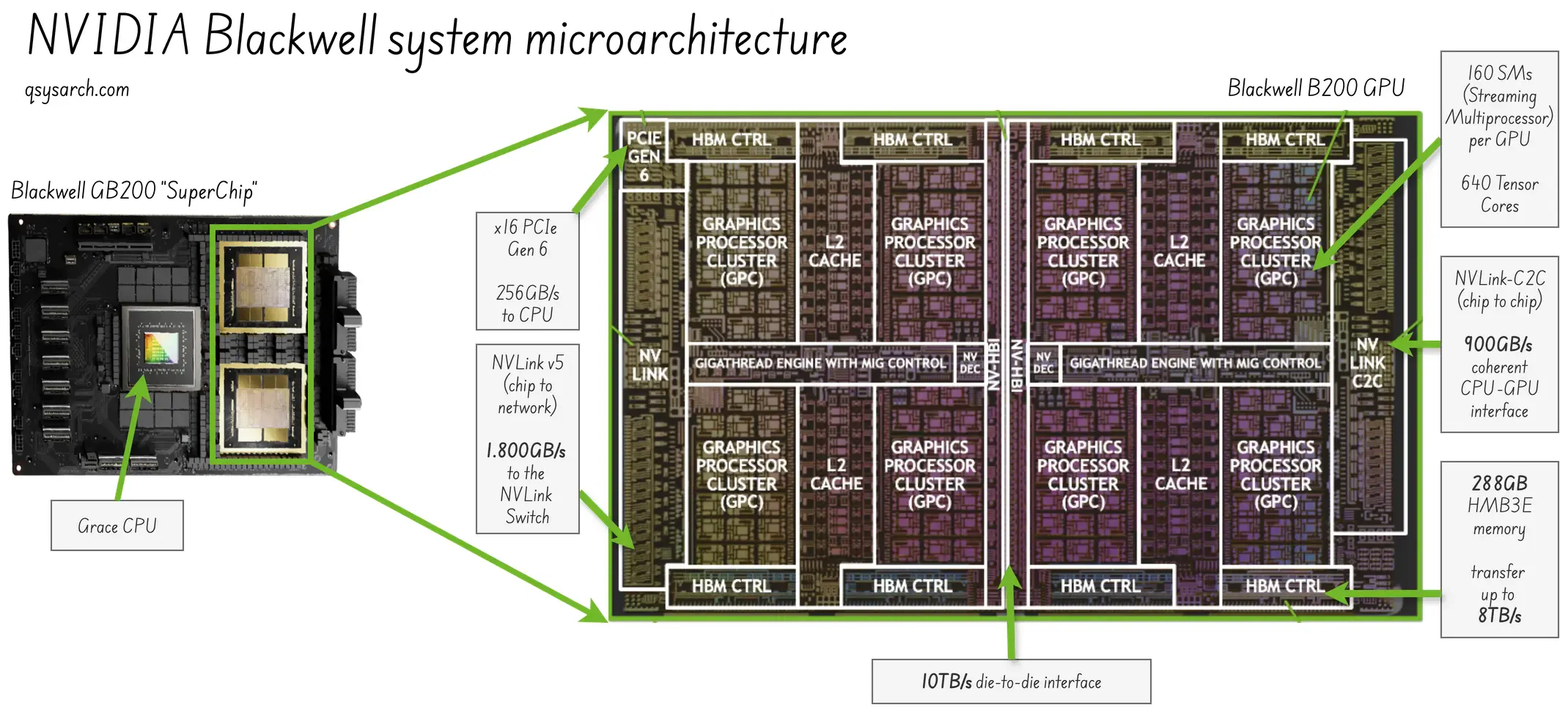
- Architecture: GPU (Blackwell architecture in 2024)
- Core Strength: Ecosystem lock-in, software stack depth, full system integration
- Target Workload: Universal — LLM training & inference at scale - Graphic Shaders
- Vulnerability: High cost, high power usage; Not optimized for sparse compute
Vertical Integrators Link to heading
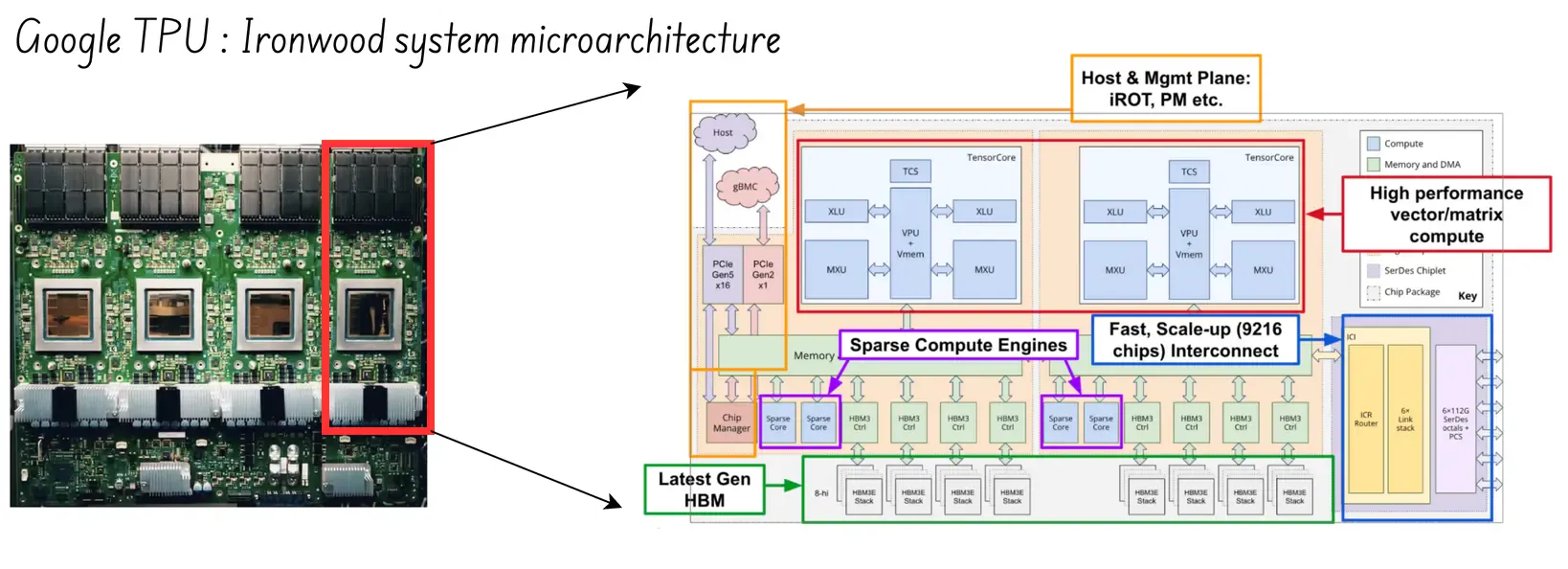
- Architecture: TPU, Custom ASIC (systolic)
- Core Strength: Vertical integration; lowest cost at Google-scale
- Target Workload: Google Cloud workloads, Gemini inference
- Vulnerability: Only available from Google cloud; Not possible to buy the TPU cores from Google
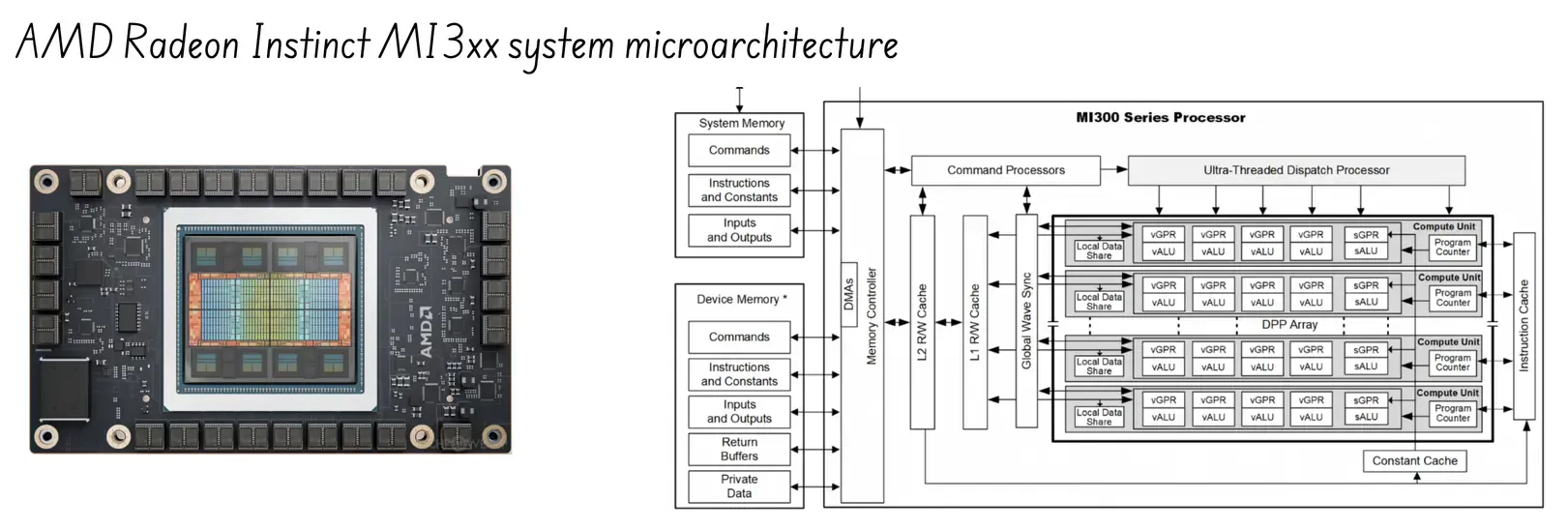
- Architecture: MI300 Instinct + ROCm (AMD’s own CUDA)
- Core Strength: CUDA pricing alternative; familiar GPU model;
- Target Workload: Cloud cost-sensitive HPC & inference
- Vulnerability: Software gap vs CUDA; Lacking behind on the forefront ecosystem (eg NVQLINK)
The already-acquired Challengers Link to heading
Groq (acquired by NVIDIA)

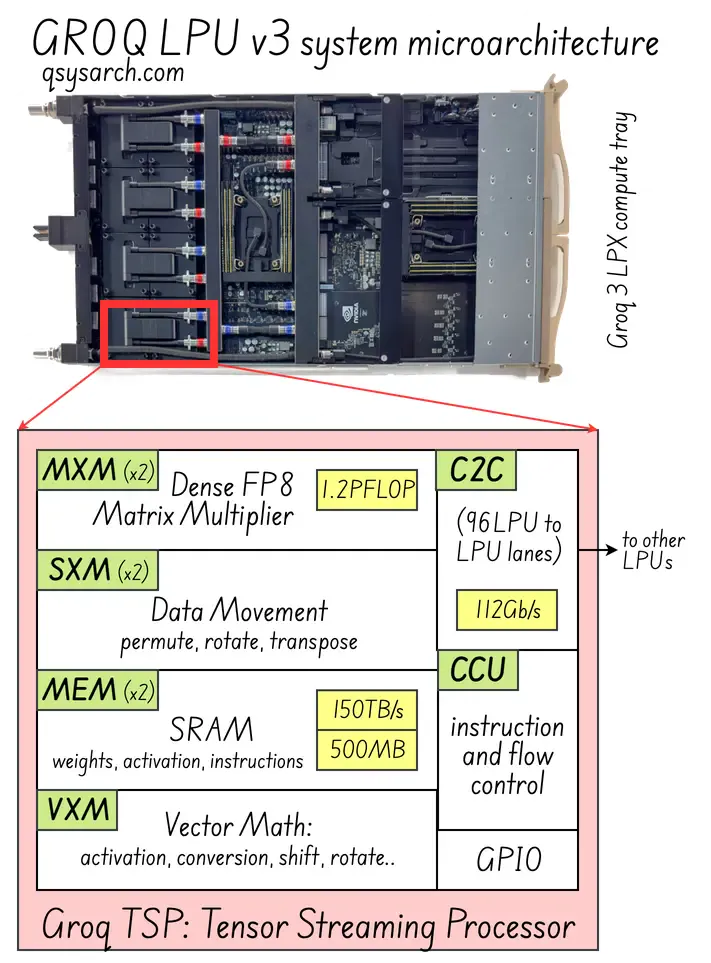
- Architecture: LPU (Language Processing Unit)
- Working principle: built around core Tensor Streaming Processor (TSP) architecture, the execution time is entirely predictable down to the exact clock cycle.
- Core Strength: Deterministic ultra-low latency; no memory bottleneck; everything is “disciplined” ahead-of-time by the compiler.
- Target Workload: Real-time inference
- Vulnerability: Trading speed for space: No large HBM (high bandwidth memory) but only small embedeed super fast SRAM (although this makes it a good complement to Nvidia Blackwell ecosystem now that it has been bought by NVIDIA!)
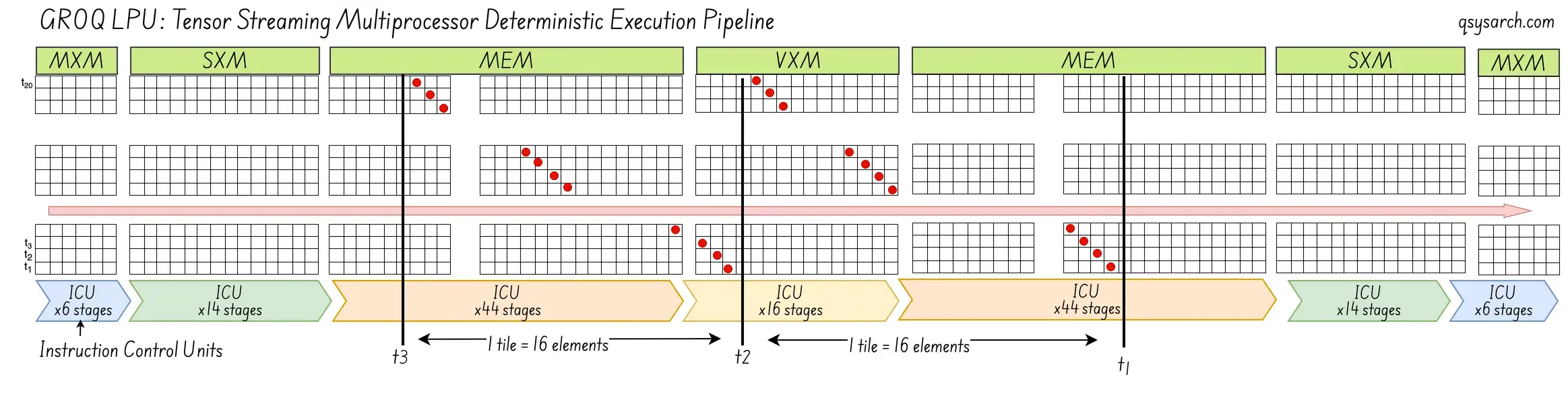
Note that the Groq LPU architecture was presented in 2020, commercially launched in 2024, and acquired in 2026. This gives a good timeline for wannabe-unicorns: 4 years for development, 2 years to confirm market traction, and the jackpot if a bigger player feels the pressure of the rivalry!
The Current Challengers Link to heading
Studying properly the solutions below could easily take a few days for each of the vendors; time which I did not have to write this memo - therefore, please take the description below with a grain of salt as it might be incomplete and/or subjective.
SambaNova [almost acquired by Intel]
- Architecture: RDU (reconfigurable dataflow unit); enables custom integrated data+processing pipelines for the entire computation graph, minimizing data movement and resulting in high hardware utilization. The diagram below shows the detailed architecture of the PCU (Pattern Compute Units) and PMU (Pattern Memory Units) used in their SN40L:
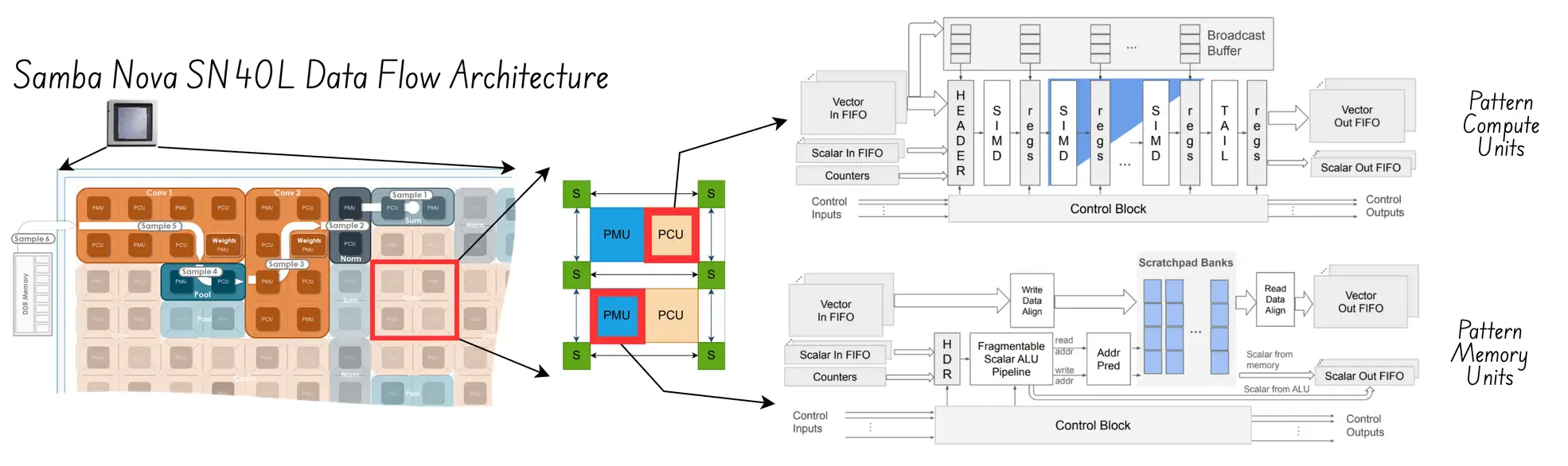
- Core Strength: Can ensure a maximum hardware utilisation by carefull partioning the system flows across the concurrent inference pipelines; Comes with a full software stack, including highlevle k8s integration, compiler for PyTorch and Tensor Flow, as well as DataFlow analyzers.
- Target Workload: Enterprise, on-prem regulated verticals.
- Vulnerability: high upfront system cost for the hardware which needs to be amortized over a long period of time for the TCO to be interresting.
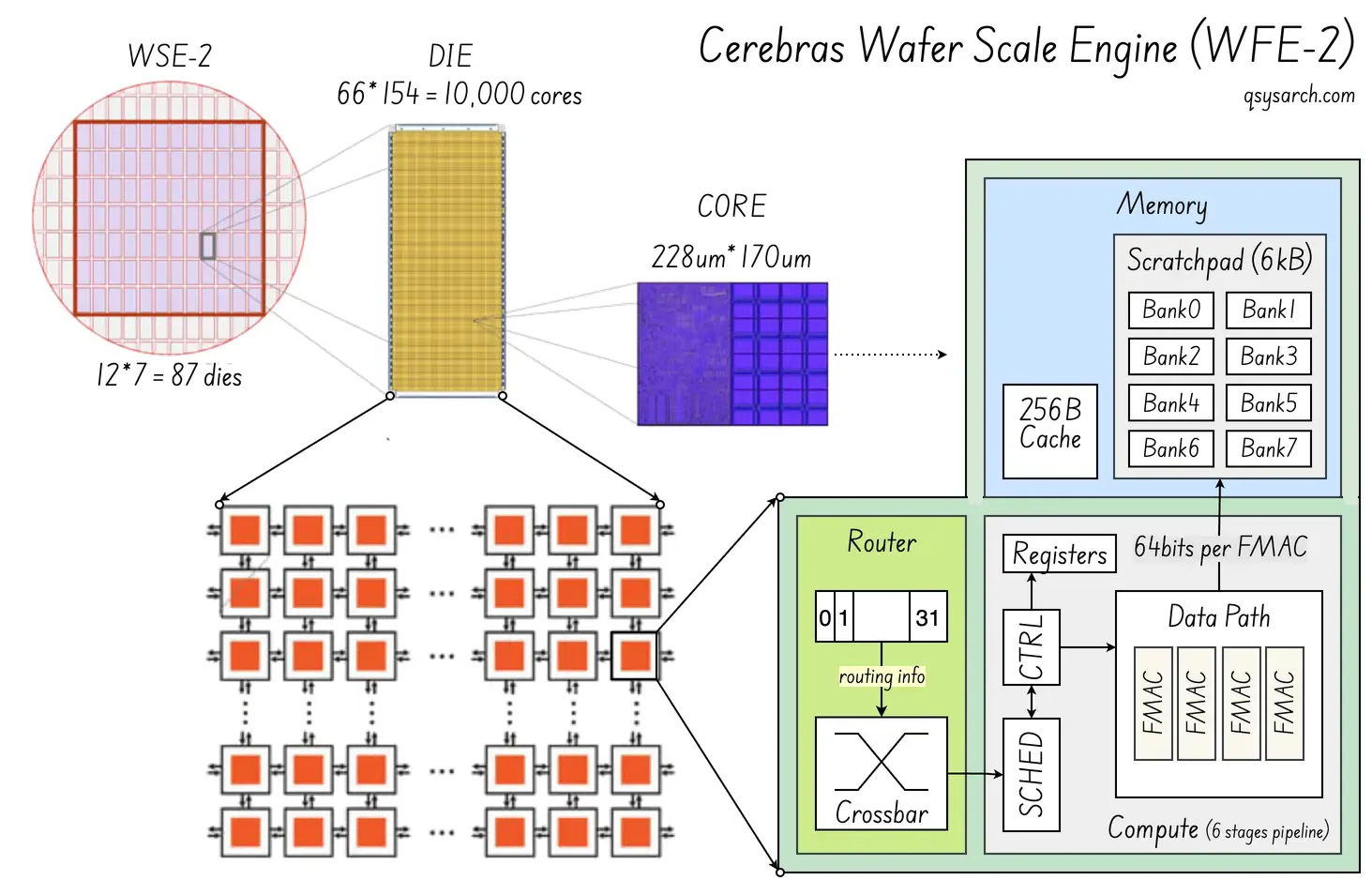
- Architecture: Wafer-Scale Engine (WSE) acting as a giant pipelined matrix multiplier.

- Core Strength: Massive on-chip SRAM that eliminates HBM bottleneck. High-density independent cores (up to 850,000 for the WSE-2) that can “tensor compute in memory”. Single-clock-latency fabric router across nodes on the wafer.
- Target Workload: Large LLM inference, especially sparse models.
- Vulnerability: Requires a top-noch software stack to fully take advantage of the massive scale (as for all the “PIM” or processing in memory microarchitectures).
- Architecture: Tensor Contraction Processor (TCP), marketed as the Renegade (RGND) Asic. Compared to TPU systolic arrays, which have a fixed grid, Furuisa’s TCP architecture uses small, configurable compute units that can be dynamically rearranged (like a super-smart NOC).
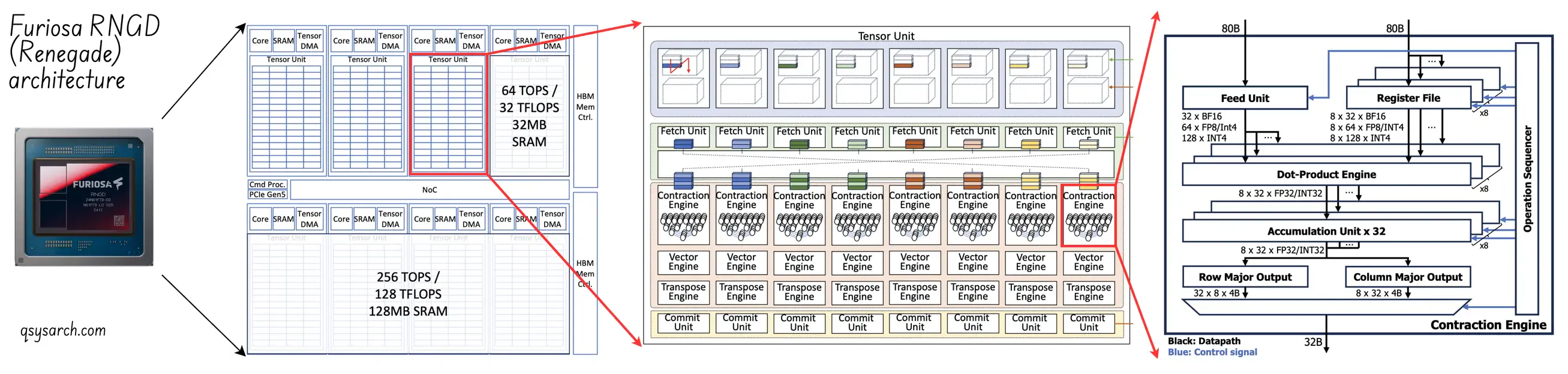
- Core Strength: By introducing the “fetch” NOC, Furiosa introduce spatio temporal programability of the TPU tensor network, bringing the efficiency level to the next stage, by perfectly fitting the compute workload and the tensors contraction processors.
- Target Workload: LLMs, VLMS,..
- Vulnerability: Limited ecosystem; geographic concentration risk (although this could play well if they capture a part of the Asian market - meaning they would be a good buy for eg Intel looking at grabbing more market share)

- Architecture: Asimov ASIC - There is not a lot of information available, but they key message that Positron gives is that memory is the king: So, if they can embedeed much more standard DDR5 memory into their asic, using chiplet stacking, then they can have a compeling offering compared to the NVIDIA blackwell with lower memory size.
- Core Strength: The focus on High Memory Bandwidth Utilization (MBU) rather than standard High Memory Bandwidth (HBM). That means that they can increase the duty cycle or utilisation rate of the memory bus, and therefor give an equivalent (or even better) memory power (bandwidth * duty cycle, as in V*I = Watts for electricity), then they could outpace the competition that would be still struggling with expensive memories.
- Target Workload: To be seen when the first Asic is availavble - but one can guess they will target standard LLMs.
- Vulnerability: Very early stage and need to find the right foundry partners; Very likely 2~4 years away from general availability and commercial solutions - will the memory still be a bottleneck by then?
The Future Challengers Link to heading
While looking for information about the above companies, I stumbled upon a few more manufacturing challengers and disruptors that could play a significant role in the coming years. And the last of them, Unconventional AI, is definitley not the least, thanks to its leader past success and vision.

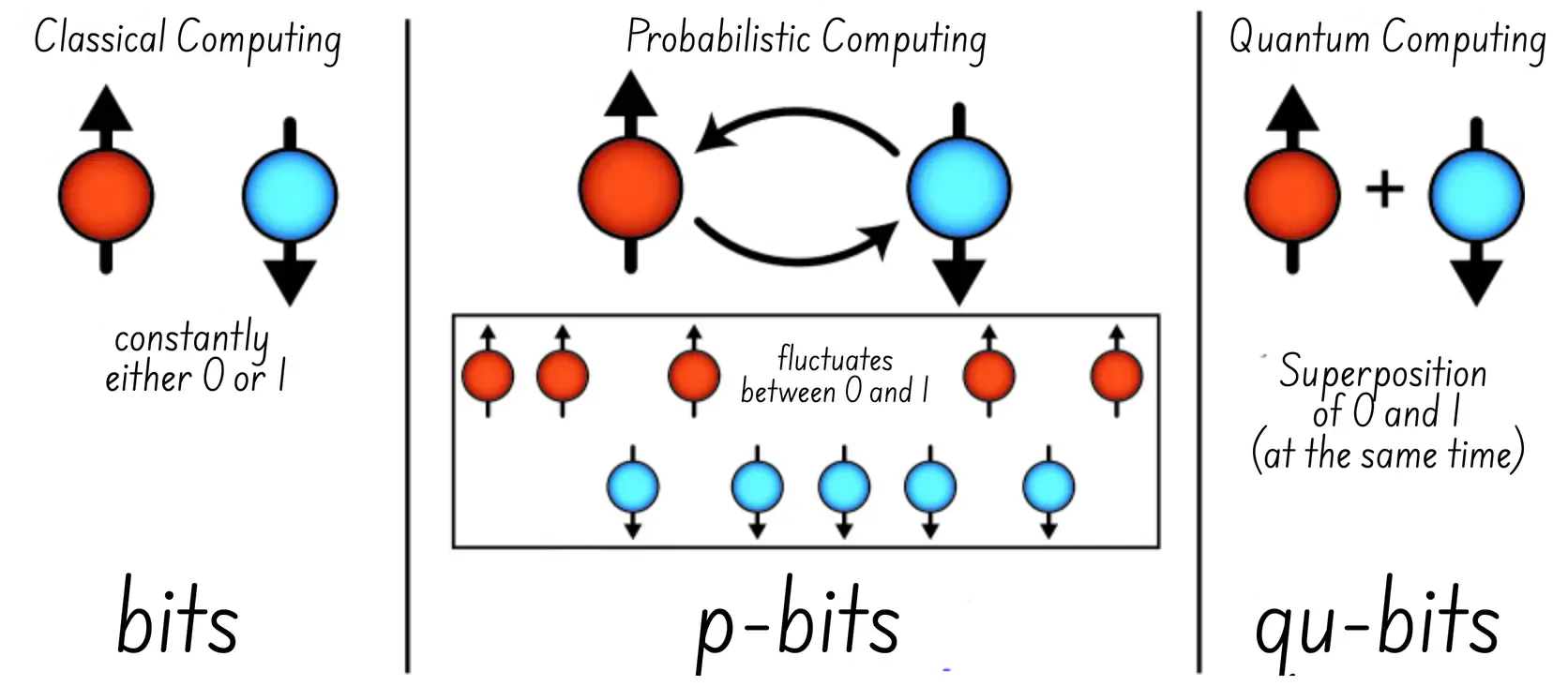
- Architecture: TSU (Thermodynamic Sampling Units) / SPU (Stochastic Processing Unit), using to operate “p-bits” (aka probabilistic bits)

- Why this matters: They claims 10,000x more efficient than GPU for specific workloads, such as Aannealing. This could pose a significant challenge for the quantum bits.
- Vulnerability: Beeing able to use at scale still needs quite some research
- Architecture: SPU (spiking neural network) using Mott memories (Mott-RAM).
- Why this matters: We need forward thinking people to look at alternative memory, such the the resistive memory (ReRAM), or, in the case of of Mottronix, the Mott RAM.
- Vulnerability: Has to prove it can move from research to productized IC.

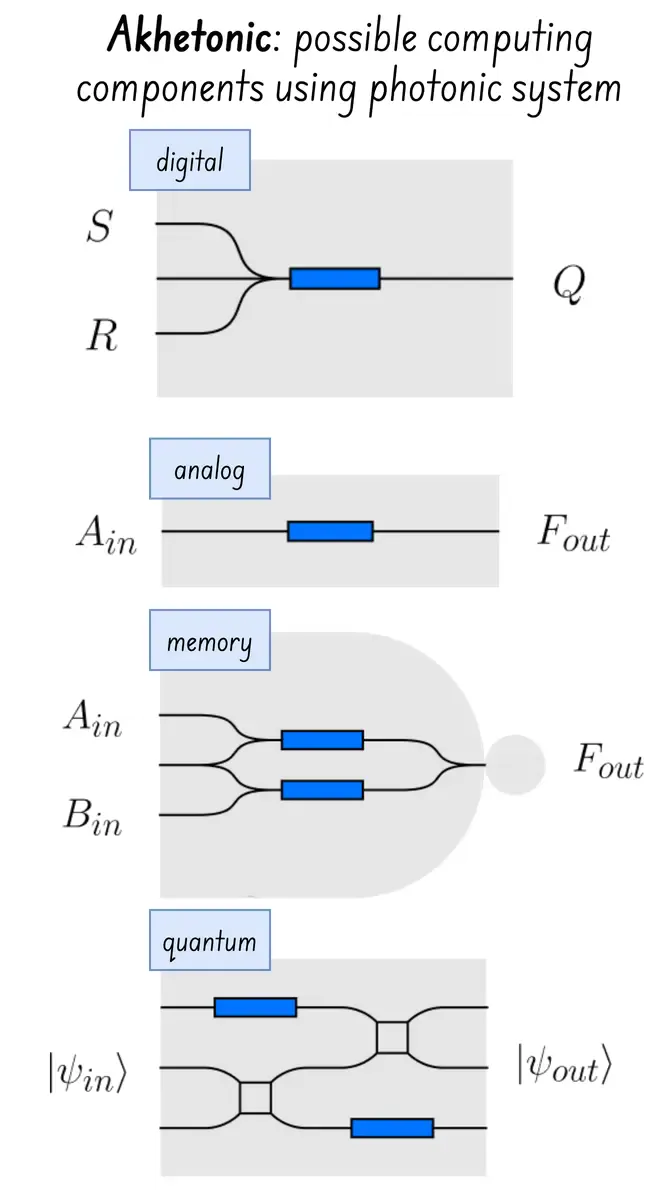
- Architecture: RPU (Reasoning Processing Unit) using all-optical digital processor
- Why this matters: Photonics IC has seen tremendous improvment of the yield over the past decade - NVIDIA is for example now able to commercially produce sillicon photonic network switch - and applying this to compute workload is a natural next step! (which also enables optically addressed quantum computation!)
- Vulnerability: It’s unclear what is the difference betwene OAQ Quantum computation and RPU reasoning computation, and in both case, it needs careful calibration and tuneup before scaling to commercial solutions.
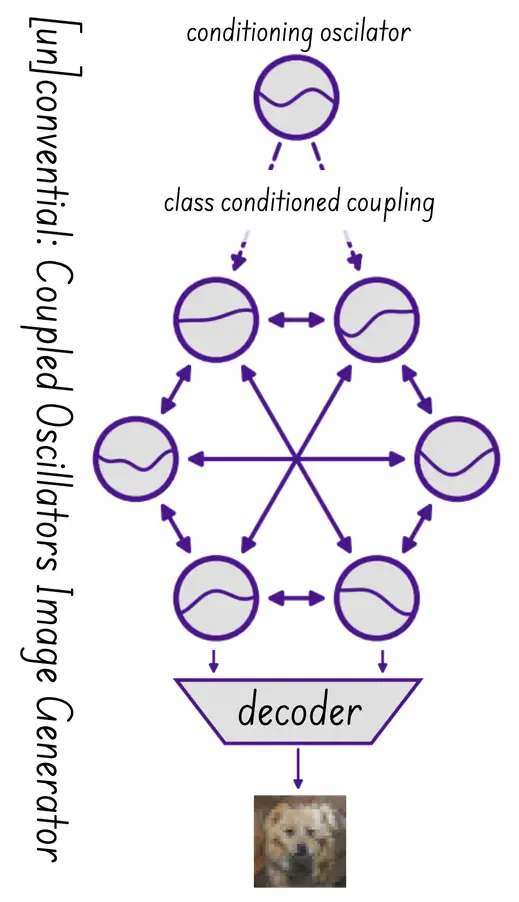
![[un]convential: Coupled Oscillators Image Generator](/images/gpxpus/unconvential-ai-coupled-oscillator-image-generator.webp#right-200px)
- Architecture: [UN]CPU ([Un]conventional Processing Unit) using Kuramoto Oscillator
- Why this matters: I love this idea, and for it to happen, execution is Key: Having the courage to think differently is only half the battle; the real world-changers put in the daily work to do it. And for this, they have a leader with impressive experience.
- Vulnerability: They are still at day 0->1, so execution is the key.
Market Retrospective in June 2026 Link to heading
Where are the current real battle lines that could change the current market landscape?
The Ecosystem: NVIDIA vs AMD Link to heading
NVIDIA’s structural advantage is not the GPU — it is the CUDA ecosystem that have been created during the past 10-years. Taking this battle requires winning on software, not just silicon - and that’s where many innovative HW-centric companies fail.
AMD is the most underrated near-term threat to NVIDIA: it does not need to beat CUDA, they have their own tool, and it just needs to be “good enough” for cost-sensitive cloud buyers. ROCm 6.x is closing the gap faster than expected.
The Innovators: The space time compromise Link to heading
Most of the innovators are trying a variation of time space compromise; either but putting more ultra fast localized memory; either by allowing dynamic configurable data flow (pipelines); As of now, the bottleneck in the RAM;
Maybe this winners are those that will be able to address both at the same time, which will even more relevant for sparse matrix computation (with many “zeros”), where one want to avoid memory transfering zeros, but also computings zeros! Could Renegade be an outside?
The Disrupters: Imperative Computing vs Dynamic Computing Link to heading
The next generation chip makers look at the computing problem from another angle: Maybe it is more about modeling and feeding a dynamic system rather than imperatively multipliying numbers one after the other?
Could the edge be a sentitive line between quantum and dynamic computing? Could this solve both the quantum cryo challenge and the qubit decoherence problem by introducing an intermediate system that enables exponential computation without incurring qubit decoherence?
Technology & Market Direction (2026~2029) Link to heading
The summary below is an opinionated vision of the tier-1 to tier-3 horizons. Three shifts will define the next cycle. They are listed in order of impact.
Memory Power™: Memory rather than compute is the quantitive power enabler Link to heading
LLMs are increasingly memory-bandwidth-bound rather than compute-bound. As models grow and context windows extend to 1M+ tokens, the cost and latency of moving weights to/from HBM dominate. The tradeoff is between near-memory compute with on-chip SRAM and large memory with sufficient bandwidth: The critical KPI could become the memory power, defined asbandwidth * duty cycle.
Mixture-of-Experts models that activate only a fraction of parameters per token (using a sparse matrix) also fall in the category: Most accelerators are not yet optimised for sparse activation patterns, and that’s why NVIDIA introduced tensor core. It may not be the final solution, but a “hardware patch” while waiting for something more consistenly robust.
Specialised Coprocessors: Need to efficiently process part of the LLM pipeline Link to heading
For example, the prefill (prompt processing) and decode (token generation) stages of an LLM have compute profiles that do not require intentive matmuls. Systems that treat them as a normal workload are efficiency sub-optimal. This opens the door for purpose-built inference co-processors and, more importantly, for a full software stack that makes efficient use of them without having to redo everything.
Tensor core for sparse Mixture-of-Experts models do fall in the category too.
HW Commoditization: Intelligence index pressure drives commoditised HW. Link to heading
Inference pricing has dropped ~10× in two years. Enterprise AI adoption is being gated by inference cost, not model quality. The implication: commodity inference hardware emerges below the high-end (NVIDIA H100/B200) for standard LLM serving. This is where challengers have the clearest window. Imagine being able to run GLM5.2 on your commodity hardware using the Positron Asimov processor!
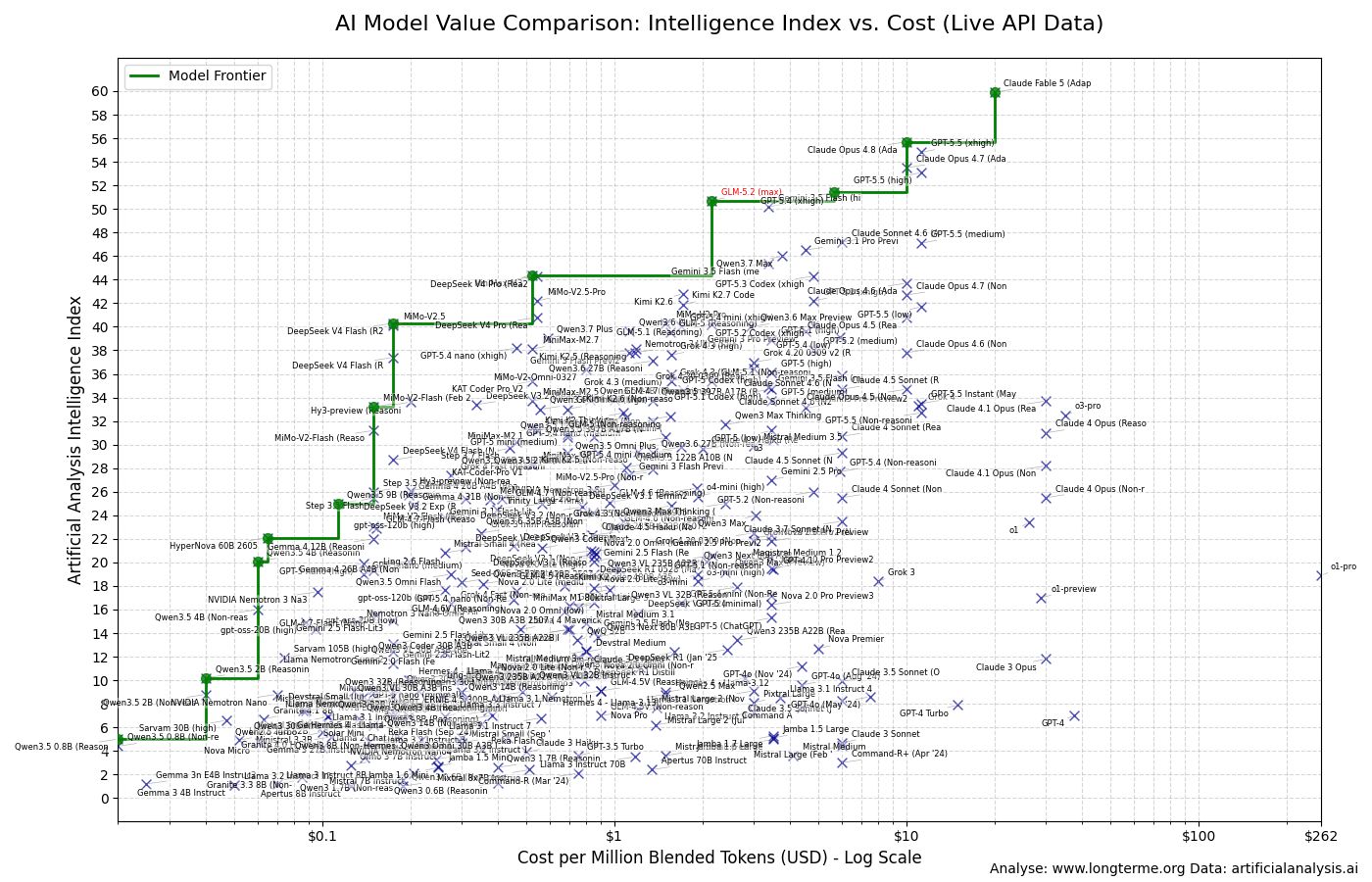 (image source: L’Observatoire du Long Terme - Z AI GLM5.2 is a clear outsider on the intelligence/cost - but requires close to 200GB of memory)
(image source: L’Observatoire du Long Terme - Z AI GLM5.2 is a clear outsider on the intelligence/cost - but requires close to 200GB of memory)
Deployment simplicity: Last but not least: ease of use for HW to SW, UI & Tools Link to heading
Enterprises consistently underestimate operational complexity. Vendors that ship “inference in a box” with zero-config runtime (not just chips) will earn a disproportionate share of the enterprise wallet.
This will be accentuated by the need for on-prem inference due to regulatory pressure in the EU and APAC, because, yes, many business do not want to infere their propreiatry knowledge on foreign system.
Conclusions Link to heading
The inference market in 2024–2026 looks like the networking market in 2000–2003. NVIDIA is like Cisco by in the days: dominant, over-engineered for many use cases, and priced at a premium. The question is not whether to challenge NVIDIA on its best workloads. It is where NVIDIA is overserving the market and where a purpose built alternative can deliver 80% of the performance at 40% of the cost.
At the same time, NVIDIA is also investing heavilly in the ecosystem, and the excellent fully opensource contributions like CudaQ and NVQLink that NVIDIA is giving away for free to the community will be it harder for any NVIDIA competitor to win those communities.
Voila, this was a short and superficial Sunday morning memo. I will have to dig more into the architectural details of the future challengers, and fortunately I will be able to have a memo for at least two of them within this summer. Meanwhile, the next memo will be about the long await topic (that quite a few readers asked me to address): Quantum Error Correction in a nutshell!
References Link to heading
- Benchmarking the Cerebras Wafer Scale Engine-2 Architecture
- Cerebras Architecture Deep Dive
- Groq LPU design
- A Thorough Investigation of Groq https://api-docs.deepseek.com/news/news260424
- MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU
- Think Fast: A Tensor Streaming Processor (TSP) for Accelerating Deep Learning Workloads
- Evolution Strategies at the Hyperscale
- HiSparse: Turbocharging Sparse Attention with Hierarchical Memory
- AscendNPU-IR
- AscendCraft: Automatic Ascend NPU Kernel Generation via DSL-Guided Transcompilation
- Fast Switching Serial and Parallel Paradigms of SNN Inference on Multi-core Heterogeneous Neuromorphic Platform SpiNNaker2
- Neuromorphic hardware for sustainable AI data centres
- A Framework for Benchmarking Neuromorphic Computing Algorithms and Systems
- Fast Switching Serial and Parallel Paradigms of SNN Inference on Multi-core Heterogeneous Neuromorphic Platform SpiNNaker2
DrawIO diagrams used in this memo:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}